Scénáře dopadu COVID-19: rychlé náhledy
Petr Bouchal
4/19/2020
source("shared.R")indikatory <- read_parquet("data-processed/scenare_vysledky.parquet")
scenarios <- read_parquet("data-processed/scenarios.parquet")
scenarios_by_year <- read_parquet("data-processed/scenarios_by_year.parquet")Scénáře
S0 je baseline, R je historický vývoj.
scenariosScénáře po letech
scenarios_by_yearPodíly obcí podle scénářů
Obce porušující pravidlo rozpočtové odpovědnosti
Pravidlo: dluh < 60 % průměru příjmů za poslední 4 roky
library(gt)
indikatory %>%
filter(per_yr %in% 2019:2022) %>%
ungroup() %>%
count(scenar = scenario_name, scenario, per_yr, wt = (rozp_odp_1yr > .6)/n(),
name = "var") %>%
spread(per_yr, var) %>%
gt() %>%
fmt_missing(columns = 1:6, missing_text = "-") %>%
fmt_percent(3:6, incl_space = T, decimals = 0, dec_mark = ",") %>%
cols_align(align = "left", columns = 1) %>%
cols_label(scenar = "Popis scénáře", scenario = "Kód scénáře")| Popis scénáře | Kód scénáře | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|
| Historie | R | 7 % | - | - | - |
| konstantní příjmy a výdaje, konstantní dluh | R0 | - | 7 % | 7 % | 7 % |
| jen propad DPH o 33 %, konstantní dluh | R0-D33-res | - | 9 % | 7 % | 7 % |
| jen propad DPH o 66 %, konstantní dluh | R0-D66-res | - | 10 % | 7 % | 7 % |
| RUD ↓ 10 %, nárůst dluhu o saldo | R10-D0-debt | - | 13 % | 18 % | 22 % |
| RUD ↓ 10 %, nárůst dluhu o půl salda | R10-D0-mix | - | 10 % | 13 % | 15 % |
| RUD ↓ 10 %, konstantní dluh | R10-D0-res | - | 8 % | 8 % | 8 % |
| DPH ↓ 33 %, zbytek RUD ↓ 10 %, nárůst dluhu o saldo | R10-D33-debt | - | 15 % | 20 % | 24 % |
| DPH ↓ 33 %, zbytek RUD ↓ 10 %, nárůst dluhu o půl salda | R10-D33-mix | - | 12 % | 13 % | 16 % |
| DPH ↓ 33 %, zbytek RUD ↓ 10 %, konstantní dluh | R10-D33-res | - | 9 % | 8 % | 8 % |
| DPH ↓ 66 %, zbytek RUD ↓ 10 %, nárůst dluhu o saldo | R10-D66-debt | - | 22 % | 23 % | 27 % |
| DPH ↓ 66 %, zbytek RUD ↓ 10 %, nárůst dluhu o půl salda | R10-D66-mix | - | 15 % | 14 % | 17 % |
| DPH ↓ 66 %, zbytek RUD ↓ 10 %, konstantní dluh | R10-D66-res | - | 10 % | 8 % | 8 % |
| RUD ↓ 20 %, nárůst dluhu o saldo | R20-D0-debt | - | 15 % | 23 % | 29 % |
| RUD ↓ 20 %, nárůst dluhu o půl salda | R20-D0-mix | - | 12 % | 15 % | 19 % |
| RUD ↓ 20 %, konstantní dluh | R20-D0-res | - | 9 % | 9 % | 9 % |
| DPH ↓ 33 %, zbytek RUD ↓ 20 %, nárůst dluhu o saldo | R20-D33-debt | - | 17 % | 24 % | 30 % |
| DPH ↓ 33 %, zbytek RUD ↓ 20 %, nárůst dluhu o půl salda | R20-D33-mix | - | 13 % | 15 % | 20 % |
| DPH ↓ 33 %, zbytek RUD ↓ 20 %, konstantní dluh | R20-D33-res | - | 9 % | 9 % | 9 % |
| DPH ↓ 66 %, zbytek RUD ↓ 20 %, nárůst dluhu o saldo | R20-D66-debt | - | 25 % | 29 % | 34 % |
| DPH ↓ 66 %, zbytek RUD ↓ 20 %, nárůst dluhu o půl salda | R20-D66-mix | - | 16 % | 17 % | 21 % |
| DPH ↓ 66 %, zbytek RUD ↓ 20 %, konstantní dluh | R20-D66-res | - | 11 % | 9 % | 9 % |
| RUD ↓ 30 %, nárůst dluhu o saldo | R30-D0-debt | - | 18 % | 30 % | 38 % |
| RUD ↓ 30 %, nárůst dluhu o půl salda | R30-D0-mix | - | 13 % | 18 % | 24 % |
| RUD ↓ 30 %, konstantní dluh | R30-D0-res | - | 10 % | 10 % | 10 % |
| DPH ↓ 33 %, zbytek RUD ↓ 30 %, nárůst dluhu o saldo | R30-D33-debt | - | 19 % | 30 % | 39 % |
| DPH ↓ 33 %, zbytek RUD ↓ 30 %, nárůst dluhu o půl salda | R30-D33-mix | - | 13 % | 18 % | 24 % |
| DPH ↓ 33 %, zbytek RUD ↓ 30 %, konstantní dluh | R30-D33-res | - | 10 % | 10 % | 10 % |
| DPH ↓ 66 %, zbytek RUD ↓ 30 %, nárůst dluhu o saldo | R30-D66-debt | - | 28 % | 36 % | 44 % |
| DPH ↓ 66 %, zbytek RUD ↓ 30 %, nárůst dluhu o půl salda | R30-D66-mix | - | 17 % | 21 % | 27 % |
| DPH ↓ 66 %, zbytek RUD ↓ 30 %, konstantní dluh | R30-D66-res | - | 11 % | 10 % | 10 % |
Obce s deficitním rozpočtem
indikatory %>%
bind_rows(indikatory %>%
filter(per_yr == 2019) %>%
select(-scenario_name) %>%
crossing(scenario_name = scenarios$scenario_name)) %>%
filter(per_yr %in% 2019:2020 & scenario %in% c("R0",
"R10-D0-debt",
"R20-D0-debt", "R30-D0-debt")) %>%
ungroup() %>%
count(scenario_name, scenario, per_yr, wt = (bilance < 0)/n()) %>%
spread(per_yr, n) %>%
gt() %>%
fmt_missing(columns = 1:3, missing_text = "-") %>%
fmt_percent(columns = 3, incl_space = T, dec_mark = ",", decimals = 0) %>%
cols_align(align = "left", columns = 1) %>%
cols_label(scenario_name = "Popis scénáře", scenario = "Kód scénáře")| Popis scénáře | Kód scénáře | 2020 |
|---|---|---|
| konstantní příjmy a výdaje, konstantní dluh | R0 | 27 % |
| RUD ↓ 10 %, nárůst dluhu o saldo | R10-D0-debt | 37 % |
| RUD ↓ 20 %, nárůst dluhu o saldo | R20-D0-debt | 47 % |
| RUD ↓ 30 %, nárůst dluhu o saldo | R30-D0-debt | 59 % |
plot_multi_percent <- function(data, category, expression,
scen_include = c("R", scenarios$scenario)) {
data %>%
bind_rows(data %>%
filter(per_yr == 2019) %>%
select(-scenario, -scenario_name) %>%
crossing(scenarios %>% select(scenario, scenario_name))) %>%
ungroup() %>%
filter(scenario %in% scen_include) %>%
group_by(per_yr, scenario_name, {{category}}) %>%
mutate(highratio = {{expression}}) %>%
summarise(perc_breach = mean(highratio, na.rm = T)) %>%
ggplot(aes(per_yr, perc_breach, colour = scenario_name)) +
geom_line(size = 0.5) +
geom_point(size = 0.8) +
# scale_color_manual(values = c("black", cols[c(7, 1:6)]), drop = T) +
facet_wrap(facets = vars({{category}})) +
scale_y_percent_cz() +
scale_x_continuous(n.breaks = 6,
labels = scales::label_number(accuracy = 1,
big.mark = "")) +
theme_ptrr("y", multiplot = T,
family = "IBM Plex Sans Condensed")
}
plot_percent <- function(data, expression,
scen_include = c("R", scenarios$scenario)) {
data %>%
bind_rows(data %>%
filter(per_yr == 2019) %>%
select(-scenario, -scenario_name) %>%
crossing(scenarios %>% select(scenario, scenario_name))) %>%
ungroup() %>%
filter(scenario %in% scen_include) %>%
group_by(per_yr, scenario_name) %>%
mutate(highratio = {{expression}}) %>%
summarise(perc_breach = mean(highratio, na.rm = T)) %>%
ggplot(aes(per_yr, perc_breach, colour = scenario_name)) +
geom_line(size = 1) +
geom_point() +
# scale_color_manual(values = c("black", cols[c(7, 1:6)]), drop = T) +
scale_y_percent_cz() +
scale_x_continuous(n.breaks = 6,
labels = scales::label_number(accuracy = 1,
big.mark = "")) +
theme_ptrr("y", multiplot = F,
family = "IBM Plex Sans Condensed")
}Bilance obcí
Otázka: kolik % obcí by v různých scénářích mělo deficitní rozpočet?
Scénáře v čase
Celkem
plot_percent(indikatory %>%
filter(per_yr < 2021),
bilance < 0, scen_include = c("R0",
"R10-D0-debt",
"R20-D0-debt",
"R30-D0-debt"))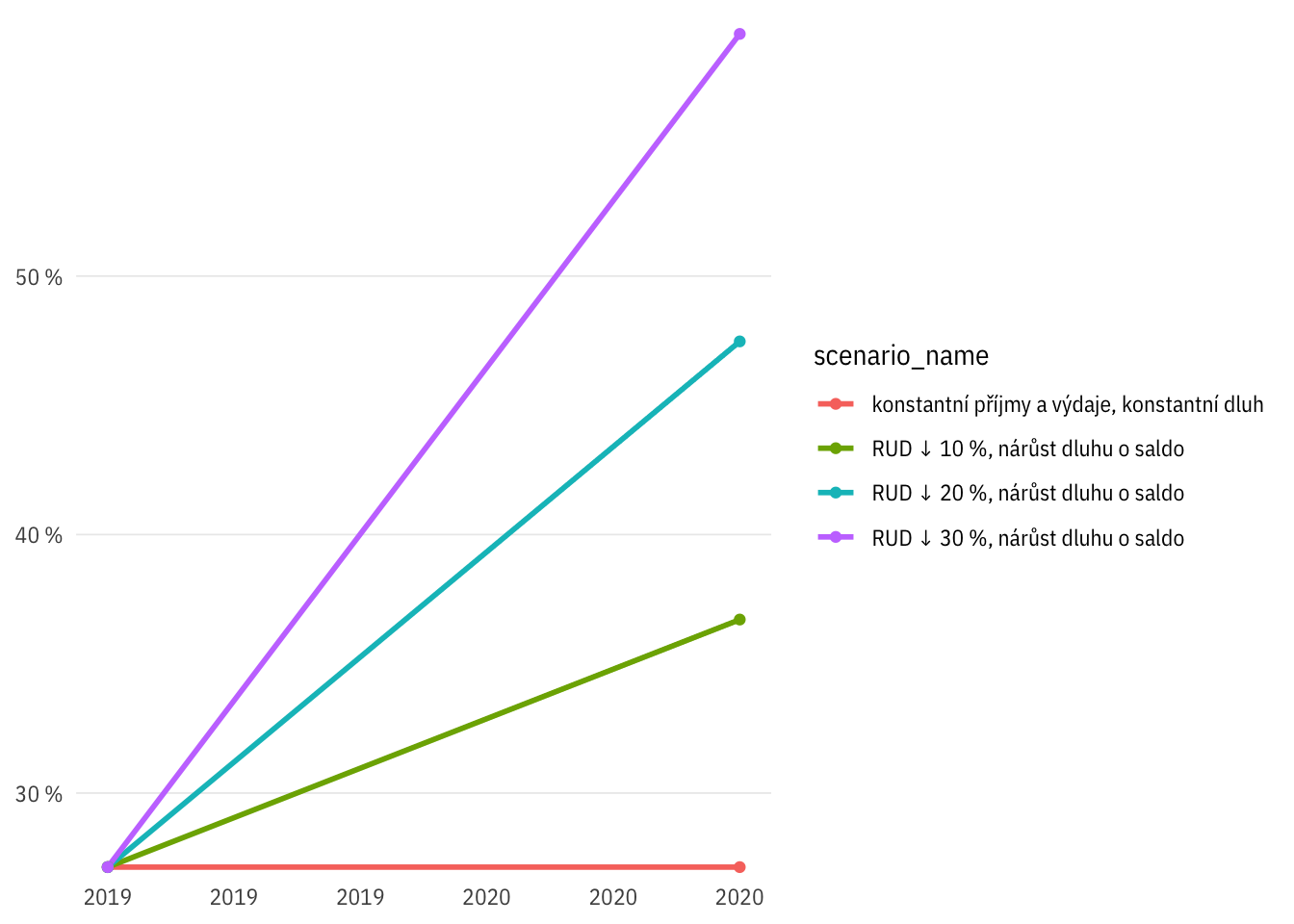
Rozdělení
indikatory %>%
filter(per_yr %in% 2019:2020,
scenario %in% c("R0",
"R10-D0-debt",
"R20-D0-debt",
"R30-D0-debt", "R"),
bilance_rel < 2.5) %>%
ggplot(aes(scenario_name, bilance_rel, fill = scenario)) +
geom_hline(yintercept = 0) +
geom_violin(colour = NA) +
scale_x_discrete(labels = scales::label_wrap(15), drop = T) +
coord_flip() +
scale_fill_manual(values = c("black", cols[c(7, 1:3)]), guide = "none") +
ptrr::theme_ptrr("scatter", legend.position = "bottom",
family = "IBM Plex Sans Condensed") +
ptrr::scale_y_percent_cz(expand = ptrr::flush_axis,
n.breaks = 8)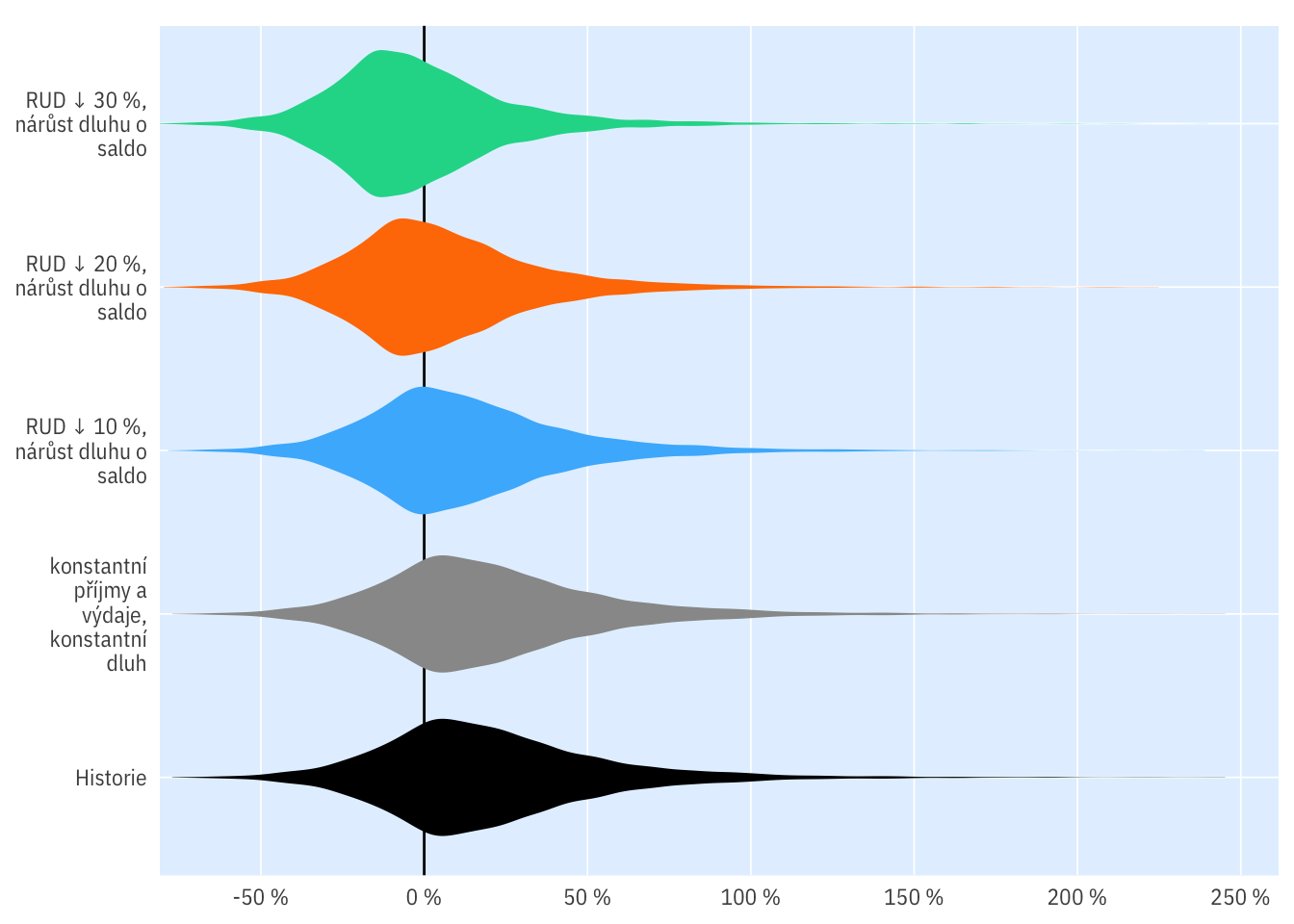
Podle krajů
plot_multi_percent(indikatory %>%
filter(per_yr < 2021),
kraj, bilance < 0, scen_include = c("R0",
"R10-D0-debt",
"R20-D0-debt",
"R30-D0-debt", "R"))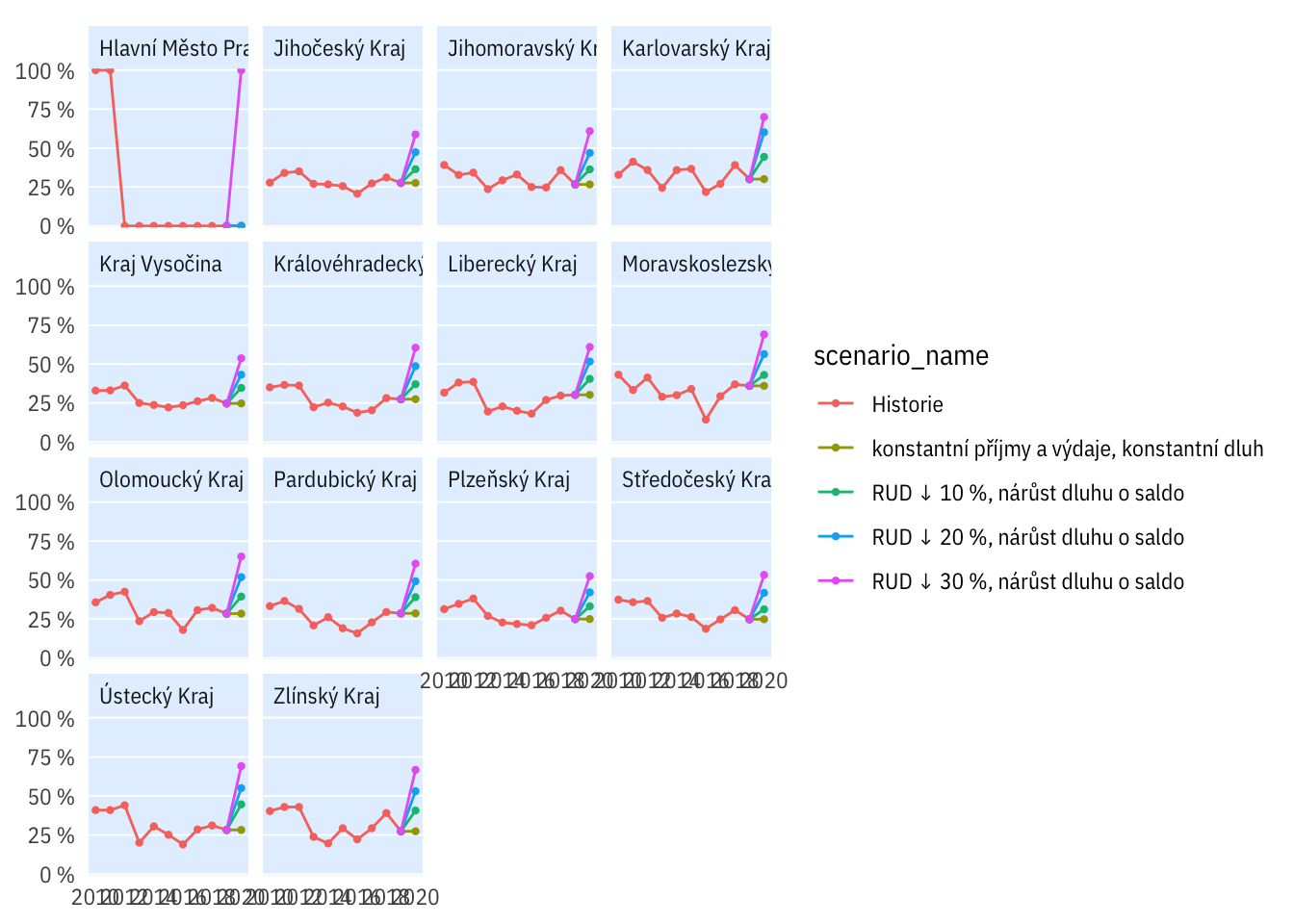
Podle velikosti obcí
plot_multi_percent(indikatory %>%
filter(per_yr < 2021),
katobyv_nazev, bilance < 0,
scen_include = c("R0",
"R10-D0-debt",
"R20-D0-debt",
"R30-D0-debt", "R"))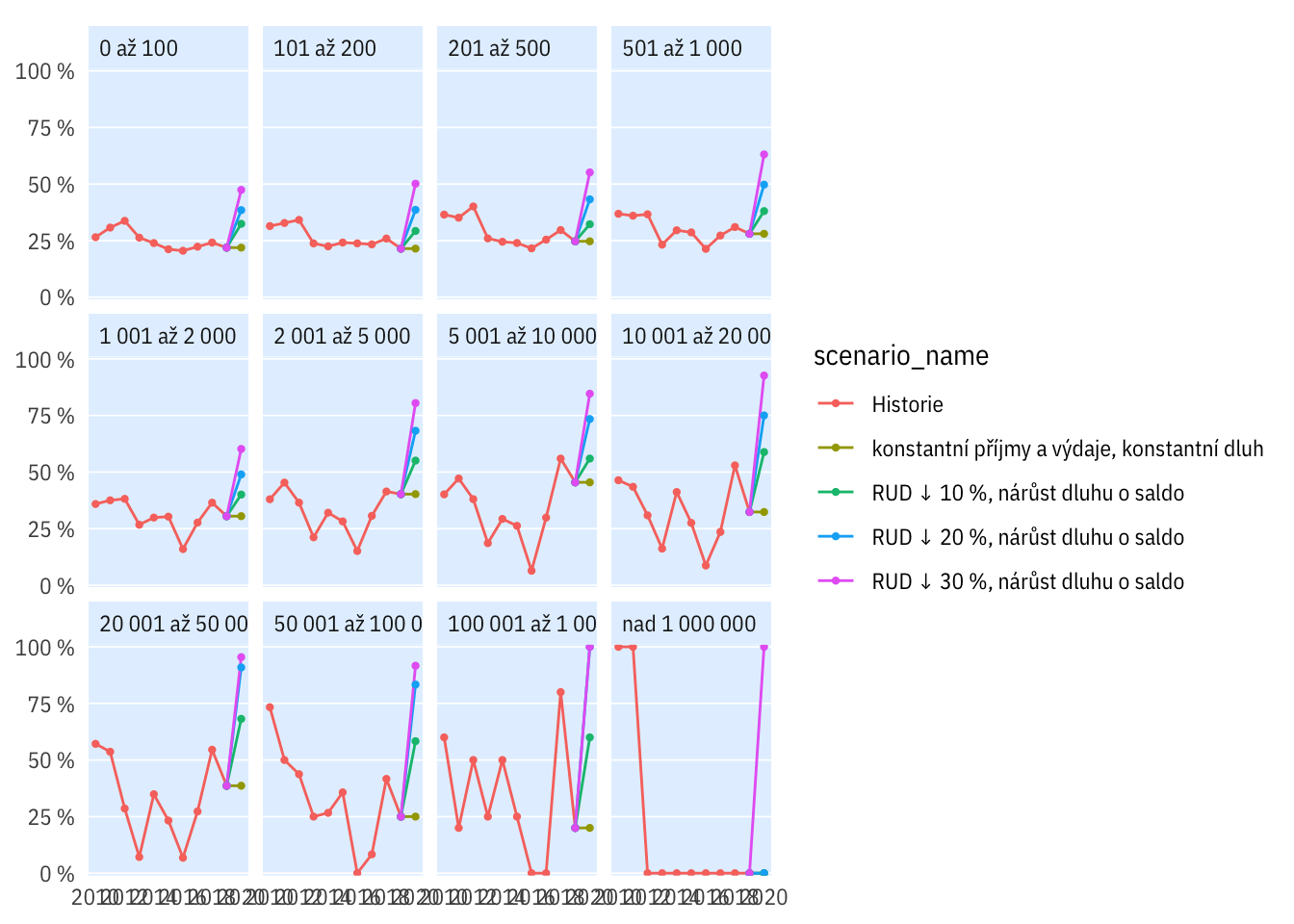
Podle druhu obcí
plot_multi_percent(indikatory %>%
filter(per_yr < 2021),
typobce, bilance < 0,
scen_include = c("R10-D0-debt","R20-D0-debt", "R30-D0-debt",
"R", "R0"))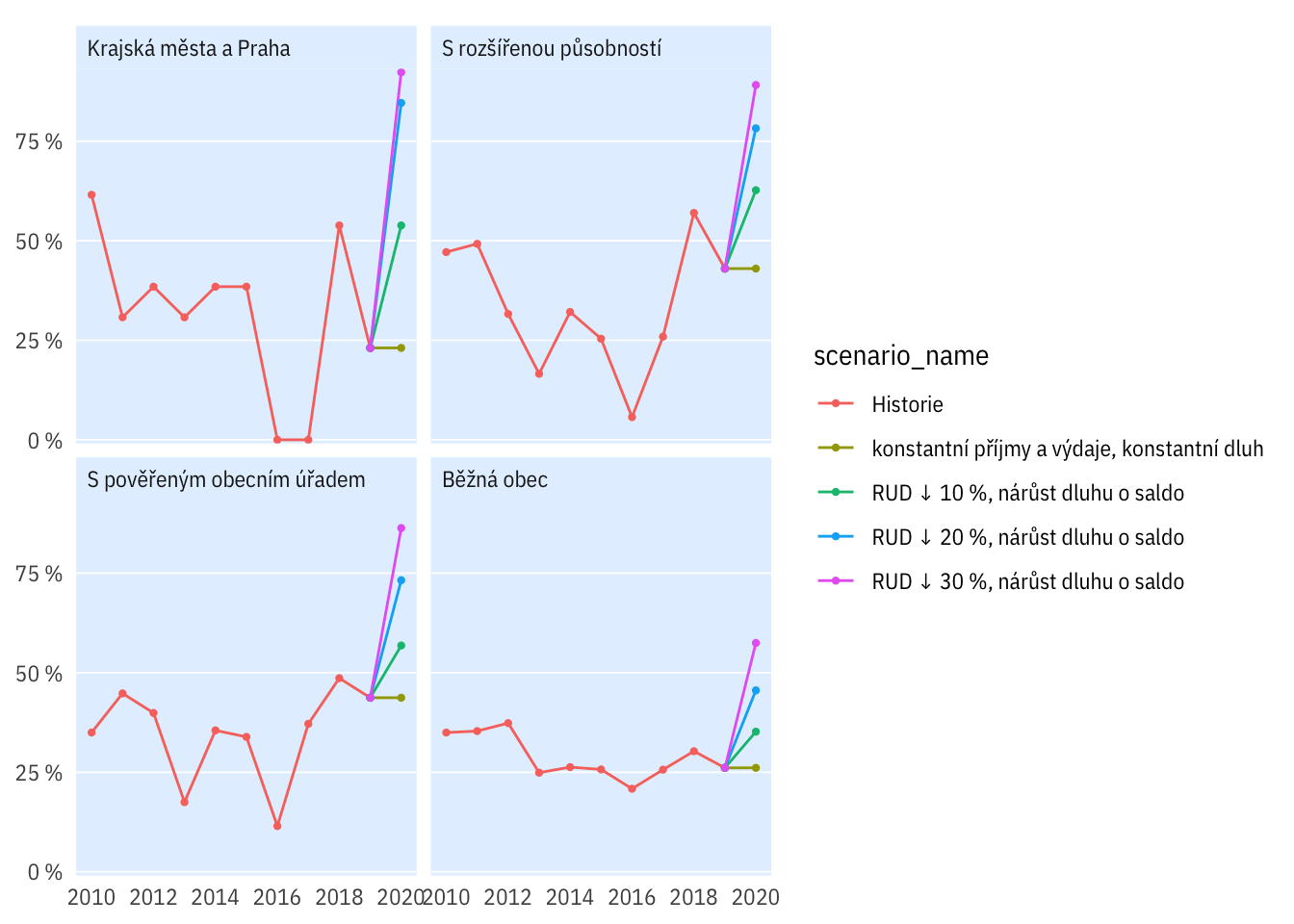
Rok 2020 oproti baseline
Celkem
indikatory %>%
filter(per_yr %in% 2019:2020,
scenario %in% c("R0", "R10-D0-debt", "R20-D0-debt", "R30-D0-debt"),
) %>%
mutate(bilance_neg = bilance < 0) %>%
group_by(scenario) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[0-3]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-3]"), names_to = "scenario") %>%
ggplot(aes(value, scenario)) +
geom_col() +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("x", multiplot = T)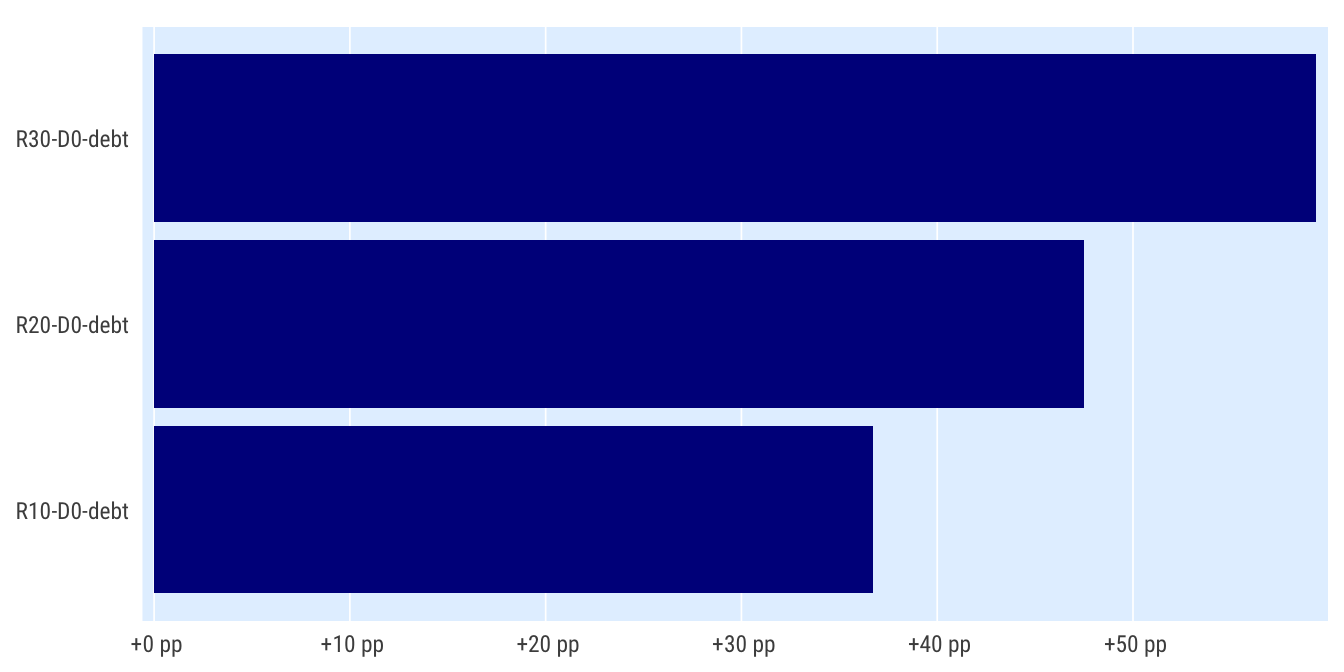
Podle kraje
indikatory %>%
filter(per_yr %in% 2019:2020,
scenario %in% c("R0", "R10-D0-debt", "R20-D0-debt", "R30-D0-debt"),
) %>%
mutate(bilance_neg = bilance < 0) %>%
group_by(scenario, grp = kraj) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[0-3]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-3]"), names_to = "scenario") %>%
mutate(grp = fct_reorder(grp, value)) %>%
ggplot(aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("x", multiplot = T)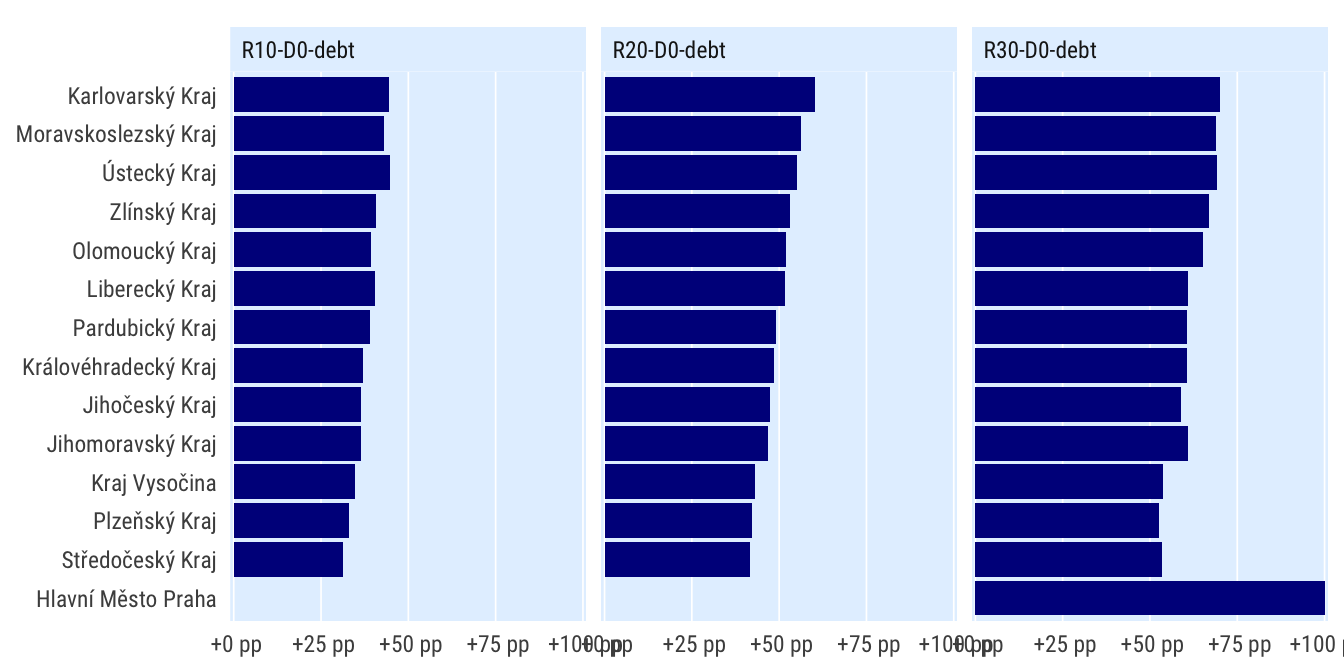
Podle velikosti obce
indikatory %>%
filter(per_yr %in% 2019:2020,
scenario %in% c("R0", "R10-D0-debt", "R20-D0-debt", "R30-D0-debt"),
) %>%
mutate(bilance_neg = bilance < 0) %>%
group_by(scenario, grp = katobyv_nazev) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[0-3]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-3]"), names_to = "scenario") %>%
# mutate(grp = fct_reorder(grp, value)) %>%
ggplot(aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("x", multiplot = T)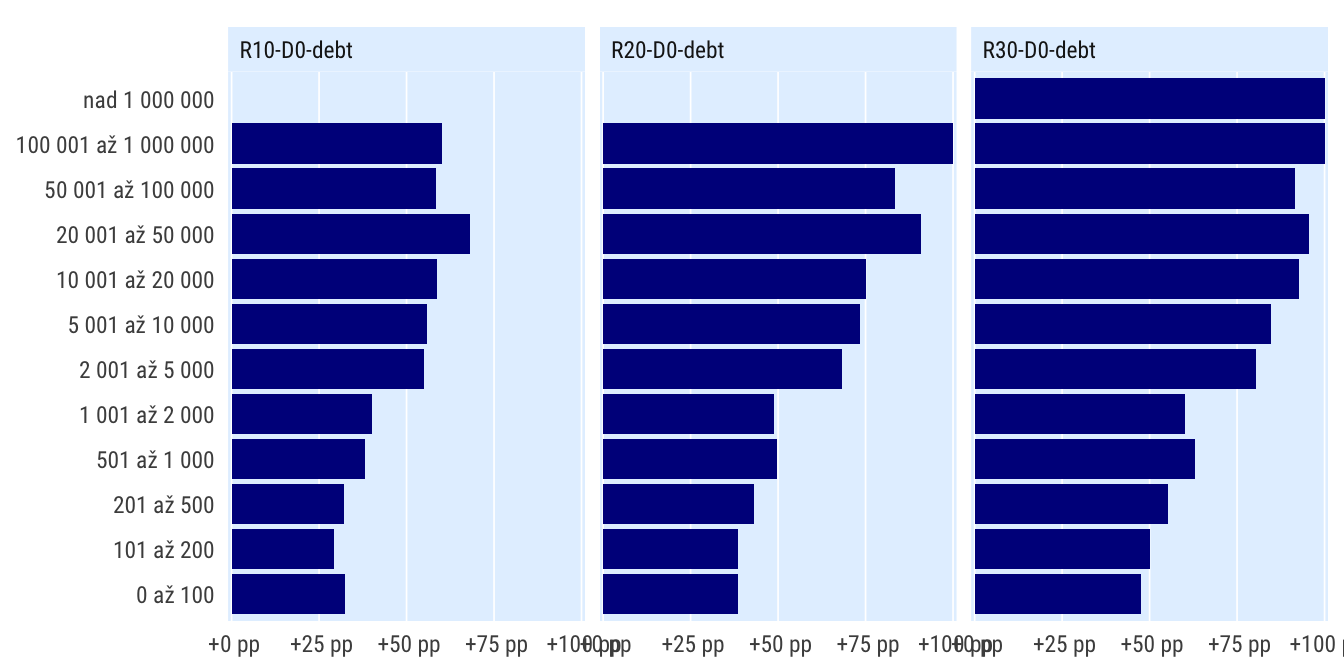
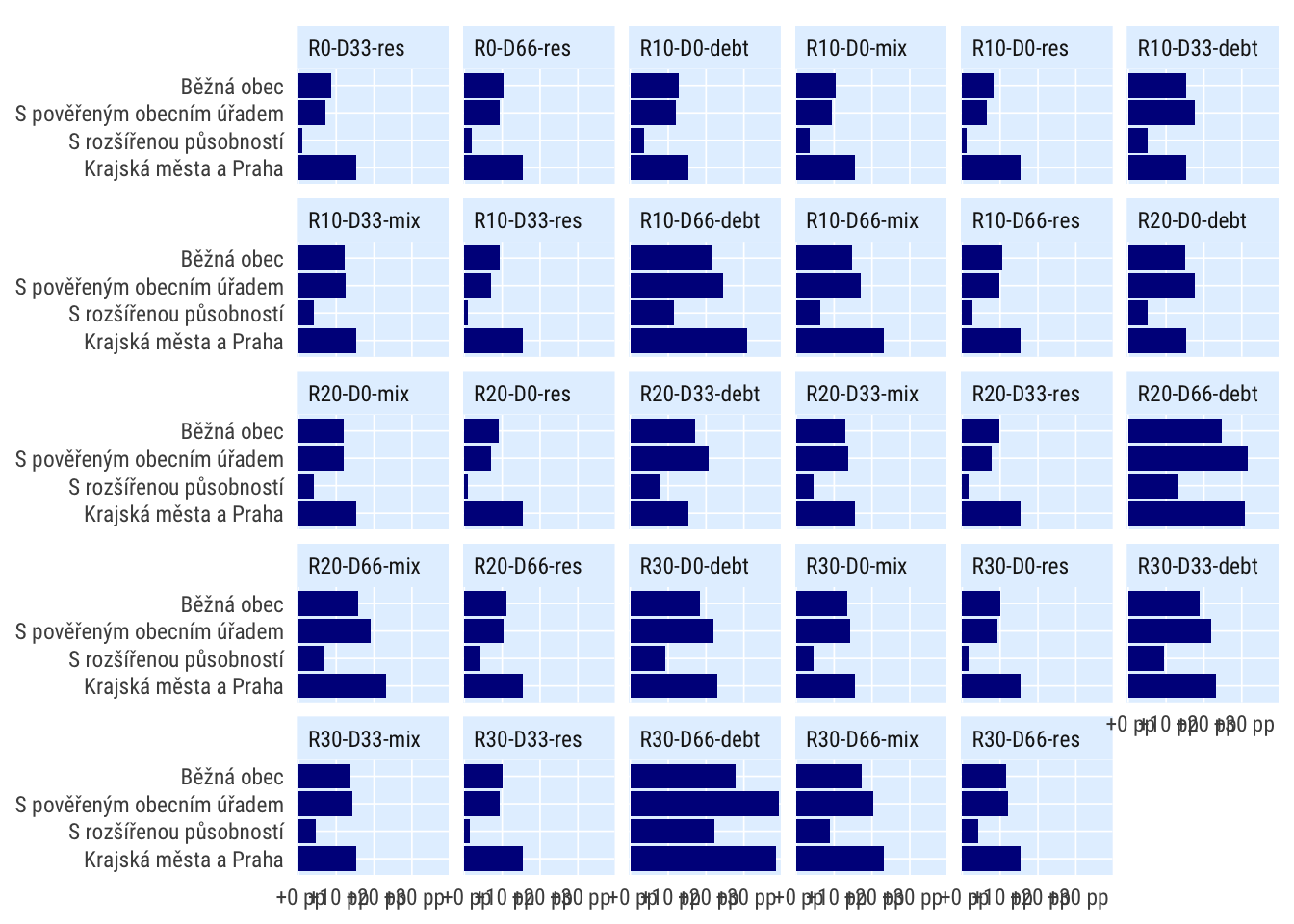
Podle druhu obce
dt_impact_typ <- indikatory %>%
filter(per_yr %in% 2019:2020,
scenario %in% c("R0", "R10-D0-debt", "R20-D0-debt", "R30-D0-debt"),
) %>%
mutate(bilance_neg = bilance < 0) %>%
group_by(scenario, grp = typobce) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[0-3]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-3]"), names_to = "scenario") %>%
# mutate(grp = fct_reorder(grp, value)) %>%
filter(TRUE)ggplot(dt_impact_typ, aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("x", multiplot = T)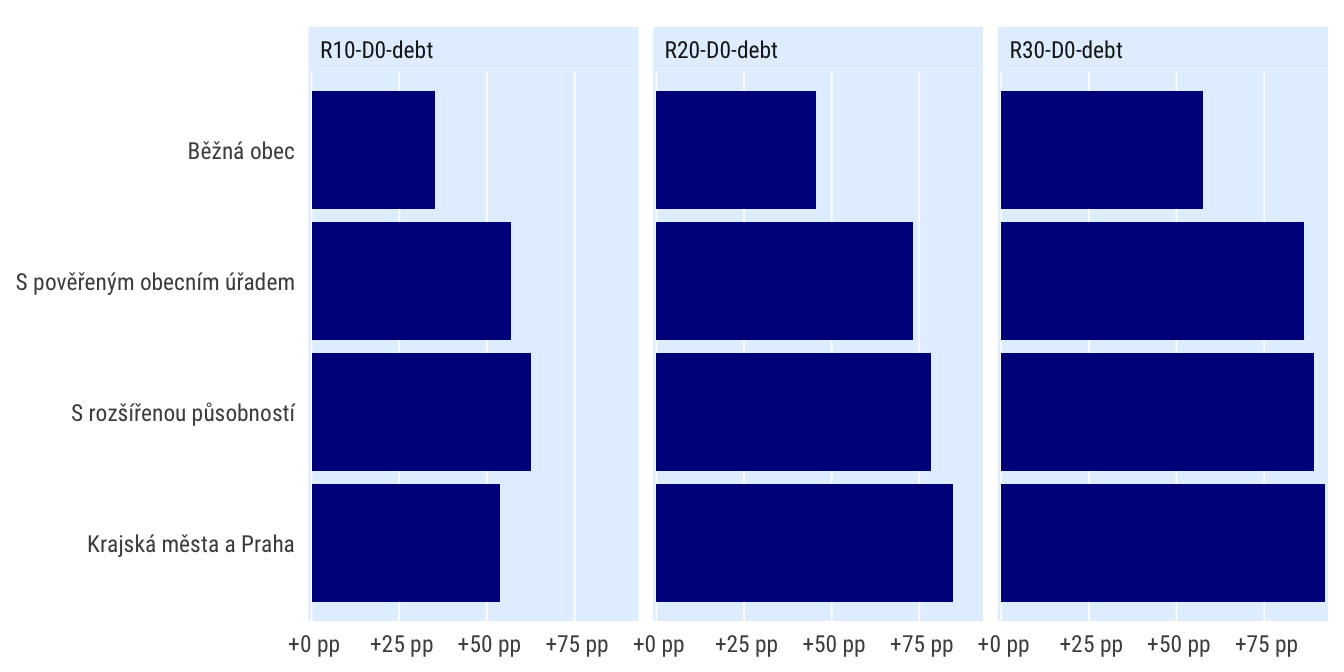
ggplot(dt_impact_typ, aes(value, grp)) +
geom_point(aes(colour = scenario)) +
# facet_wrap(~scenario) +
scale_color_discrete() +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("x", multiplot = T)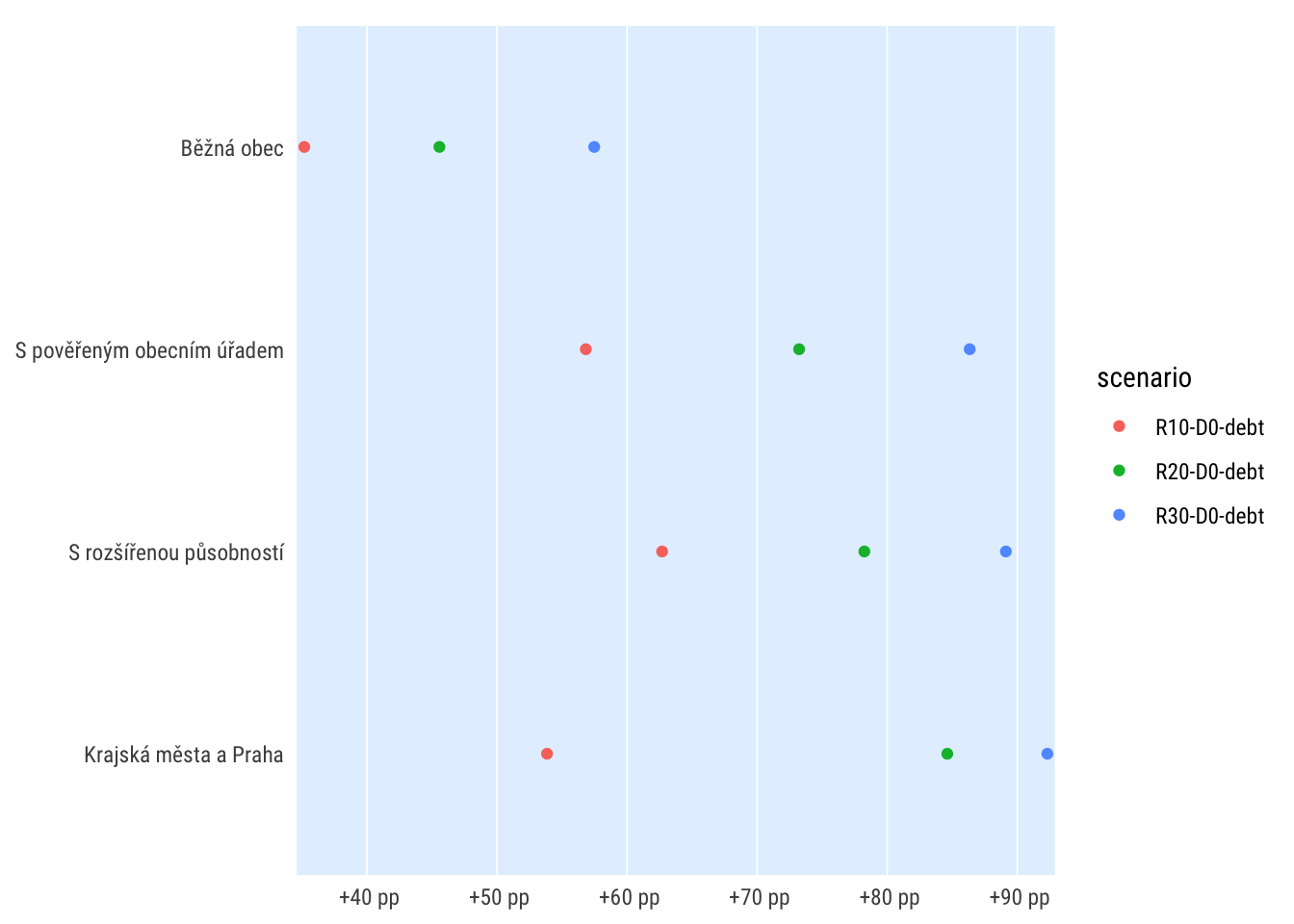
indikatory %>%
filter(per_yr %in% 2019:2020 & scenario %in% c("R0", "R10-D0-debt",
"R20-D0-debt", "R30-D0-debt")) %>%
mutate(bilance_neg = bilance < 0) %>%
group_by(per_yr, scenario_name, typobce) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
ggplot(aes(typobce, perc_minus, colour = scenario_name)) +
geom_point() +
coord_flip() +
ptrr::theme_ptrr("scatter", legend.position = "bottom",
legend.title = element_blank(),
family = "IBM Plex Sans Condensed") +
ptrr::scale_y_percent_cz()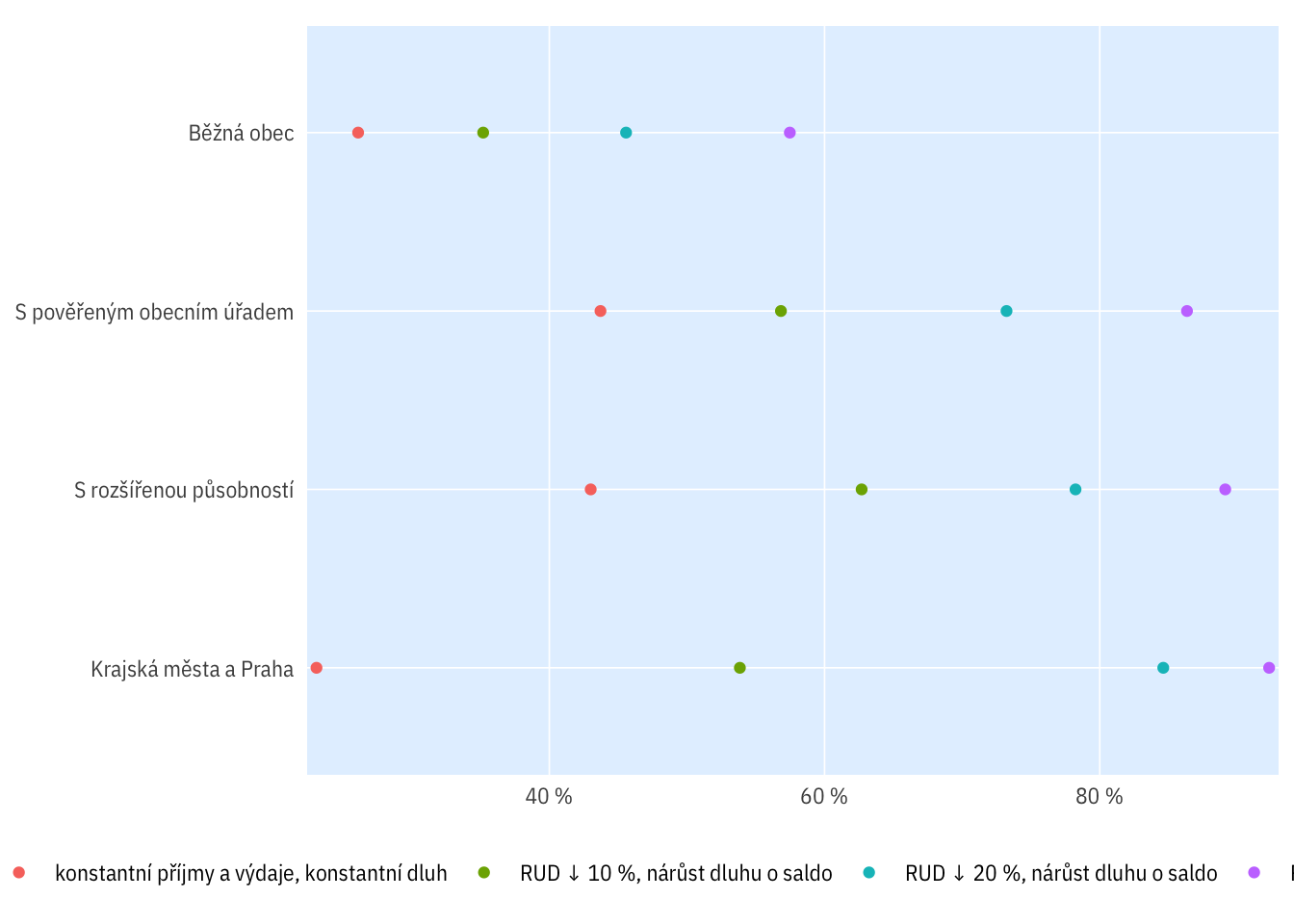
Rozpočtová odpovědnost
Otázka: kolik procent obcí by v různých scénářích porušoval pravidlo rozpočtové odpovědnosti? (dluh > 60 % průměrů příjmů z posledních 4 let)
Scénáře v čase
Celkem
plot_percent(indikatory %>% filter(per_yr > 2012,
str_detect(scenario, "D0-")),
rozp_odp > 0.6) +
expand_limits(y = c(0, 0.35))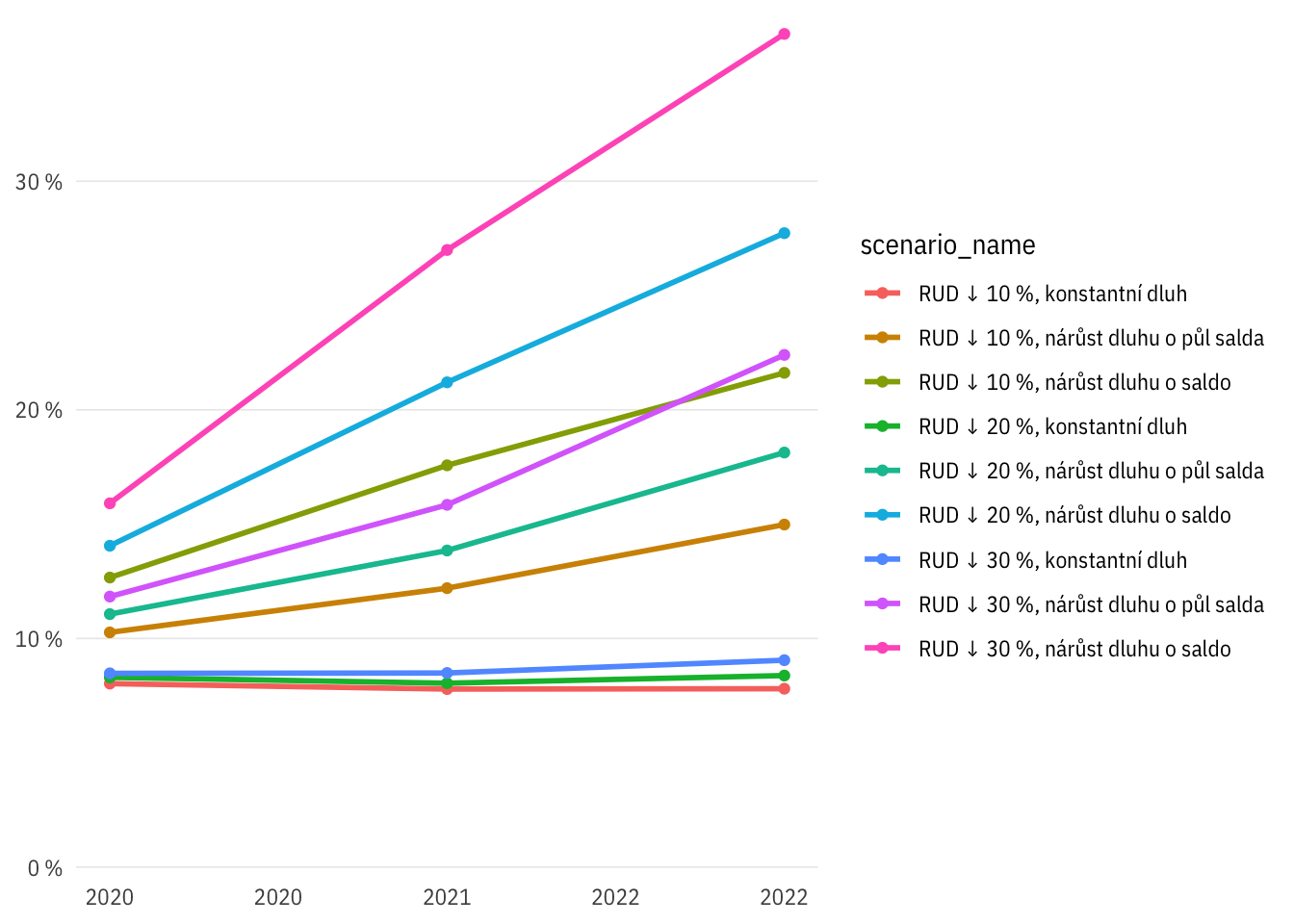
Rozdělení
indikatory %>%
filter(per_yr %in% 2019:2020,
str_detect(scenario, "D0"),
rozp_odp < 2.5) %>%
ggplot(aes(scenario, rozp_odp, fill = scenario)) +
geom_hline(yintercept = 0.6) +
# stat_ecdf(geom = "step", ) +
geom_violin(colour = NA) +
scale_x_discrete(labels = scales::label_wrap(15), drop = T) +
coord_flip() +
# scale_fill_manual(values = c("black", cols[c(7, 1:6)]), guide = "none") +
ptrr::theme_ptrr("scatter", legend.position = "bottom",
family = "IBM Plex Sans Condensed", multiplot = T) +
ptrr::scale_y_percent_cz(expand = ptrr::flush_axis,
n.breaks = 8)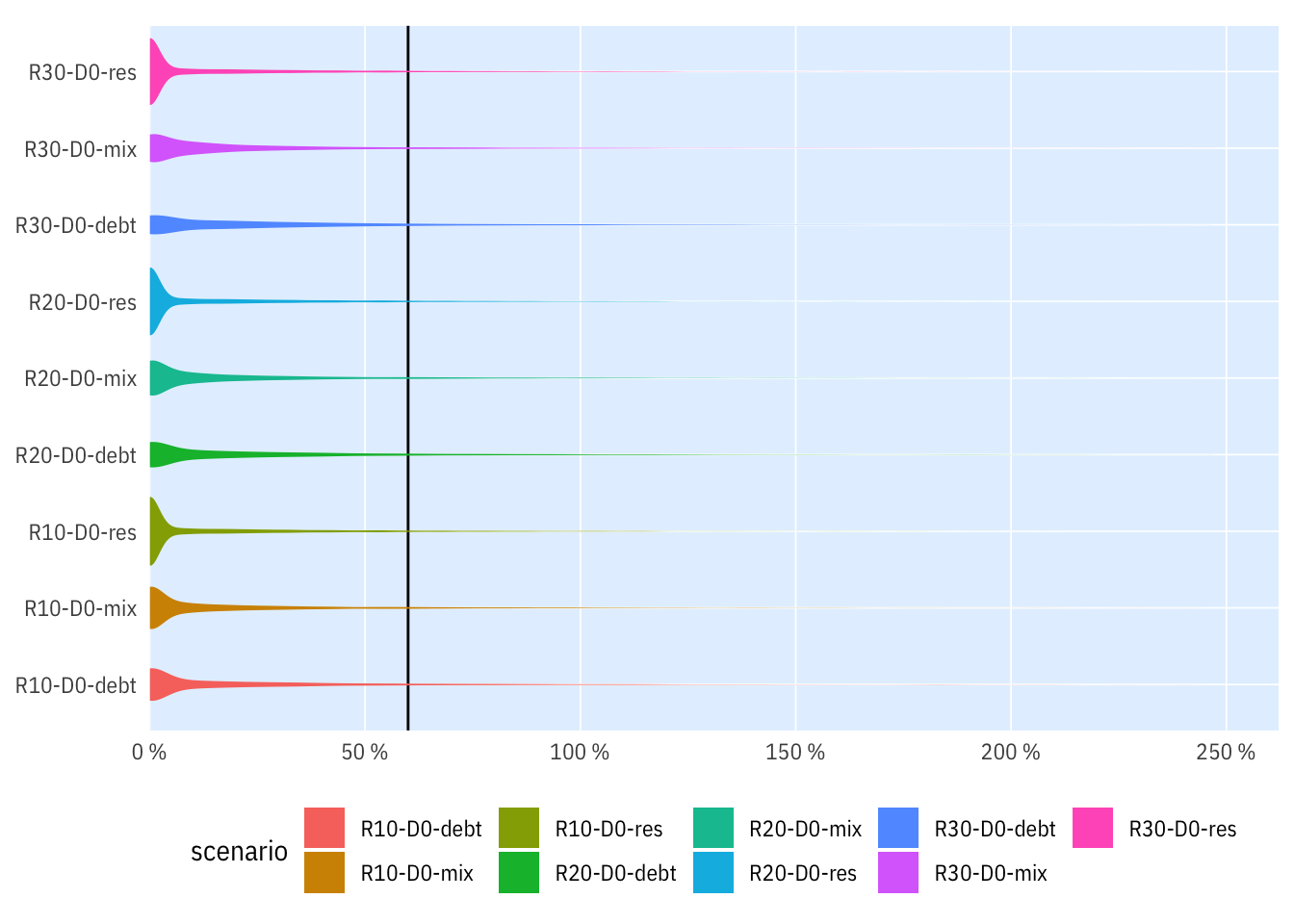
Podle kraje
plot_multi_percent(indikatory %>% filter(per_yr > 2012,
str_detect(scenario, "D0-mix")),
kraj, rozp_odp > 0.6) +
expand_limits(y = c(0, 0.45)) +
theme(legend.position = "bottom", legend.title = element_blank()) +
guides(colour = guide_legend(nrow = 4))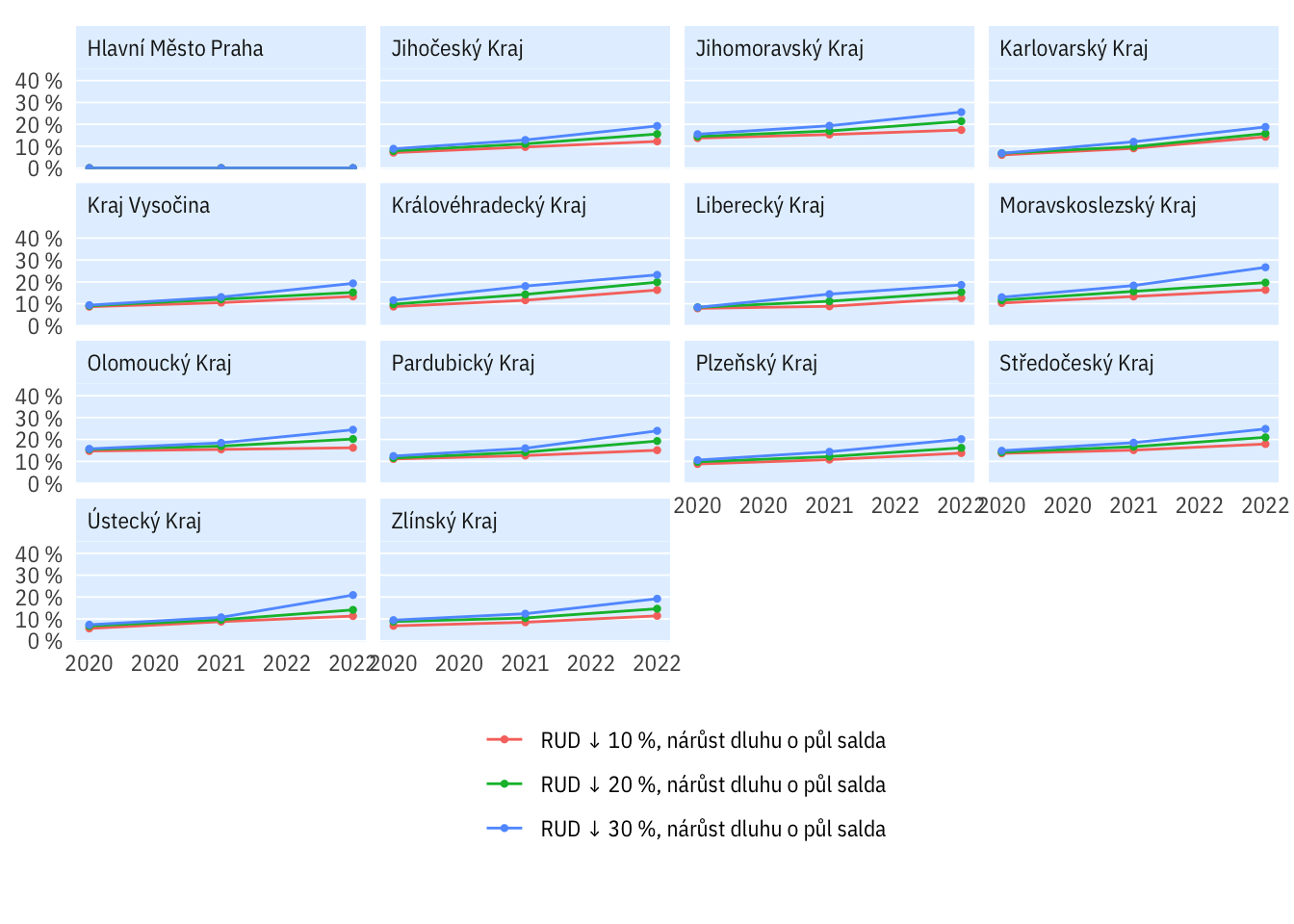
Podle velikosti obcí
scend0 <- scenarios[str_detect(scenarios$scenario, "^R$|D0"),] %>% pull(scenario)
plot_multi_percent(indikatory, katobyv_nazev, rozp_odp > 0.6,
scen_include = scend0) +
theme(legend.position = "bottom", legend.title = element_blank()) +
guides(colour = guide_legend(nrow = 4))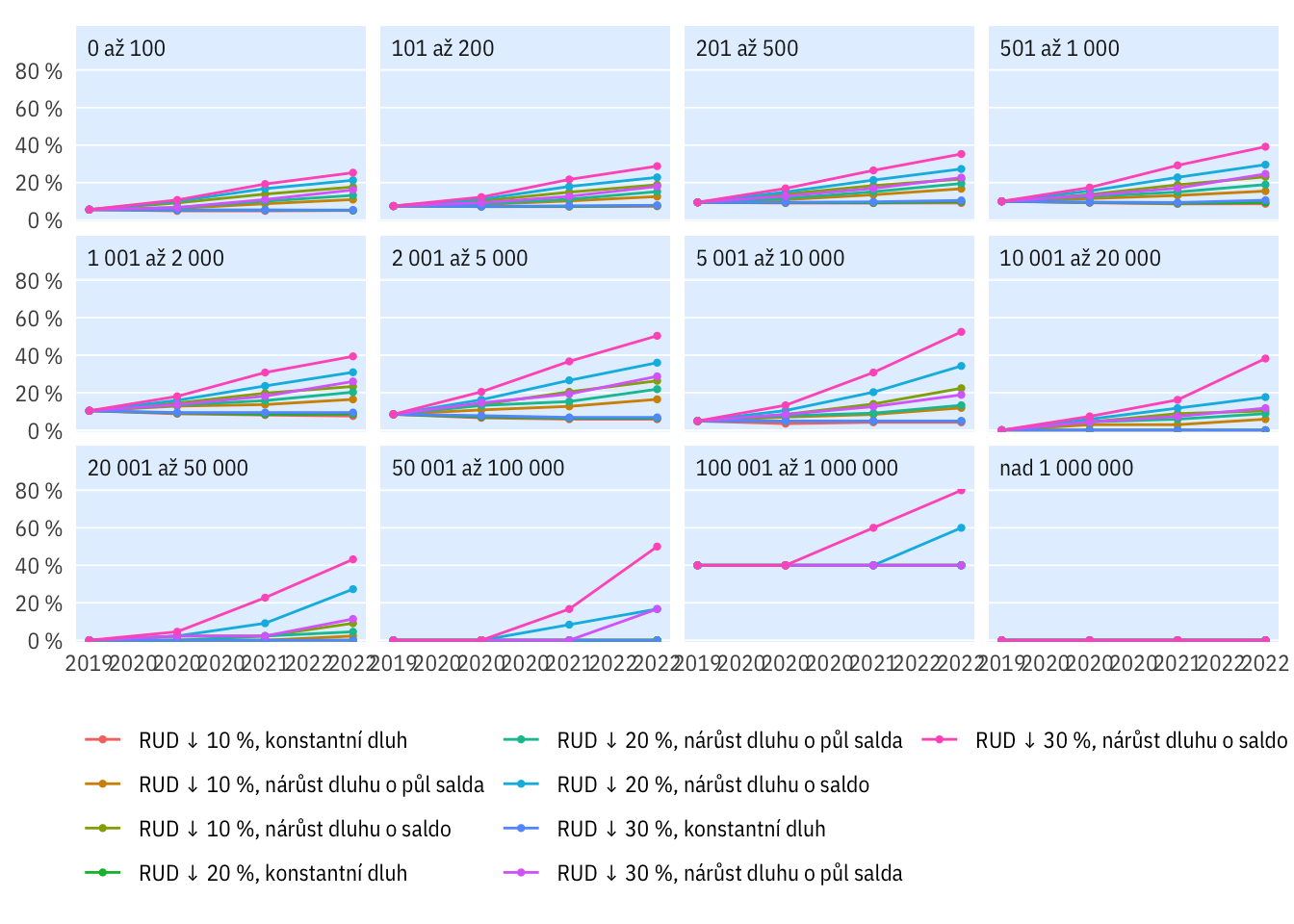
Podle druhu obcí
plot_multi_percent(indikatory %>%
filter(per_yr > 2012,
str_detect(scenario, "D0-")),
typobce, rozp_odp > 0.6) +
theme(legend.position = "bottom", legend.title = element_blank()) +
guides(colour = guide_legend(nrow = 4)) +
scale_colour_discrete()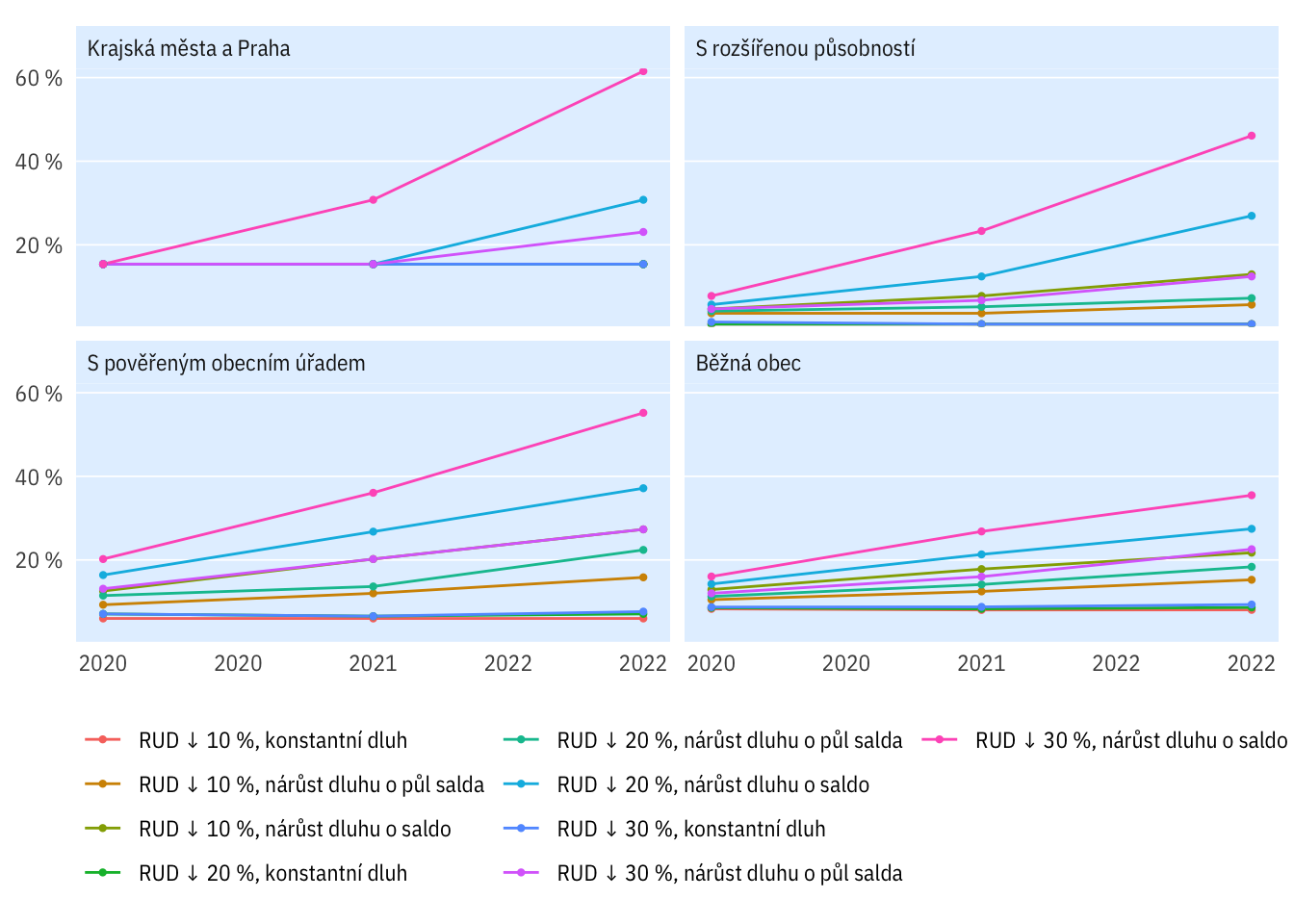
Rok 2020 oproti baseline
Celkem
indikatory %>%
filter(per_yr %in% c(2019:2020),
# scenario %in% c("S1", "S4", "S0"),
) %>%
mutate(bilance_neg = rozp_odp > 0.6) %>%
group_by(scenario) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[1-9]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-3]"), names_to = "scenario") %>%
ggplot(aes(value, scenario)) +
geom_col() +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("x", multiplot = T)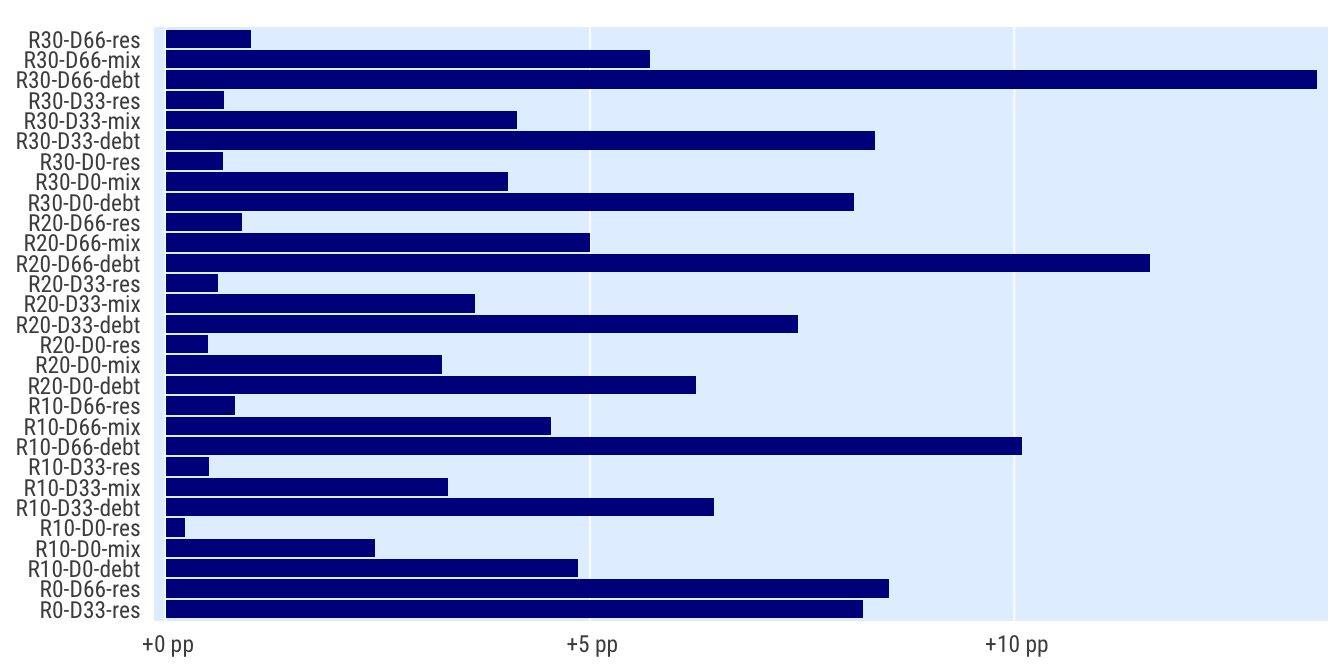
Podle kraje
indikatory %>%
filter(per_yr %in% 2019:2020,
# scenario %in% c("S1", "S4", "S0"),
) %>%
mutate(bilance_neg = rozp_odp > .6) %>%
filter(str_detect(scenario, "R(0|10|20|30)*(\\-(0|33|66))*")) %>%
group_by(scenario, grp = kraj) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("^R[0-9]")), ~./R0) %>%
select(-R0, -R) %>%
pivot_longer(cols = starts_with("R"), names_to = "scenario") %>%
# mutate(grp = fct_reorder(grp, value)) %>%
ggplot(aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
# scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("both", multiplot = T)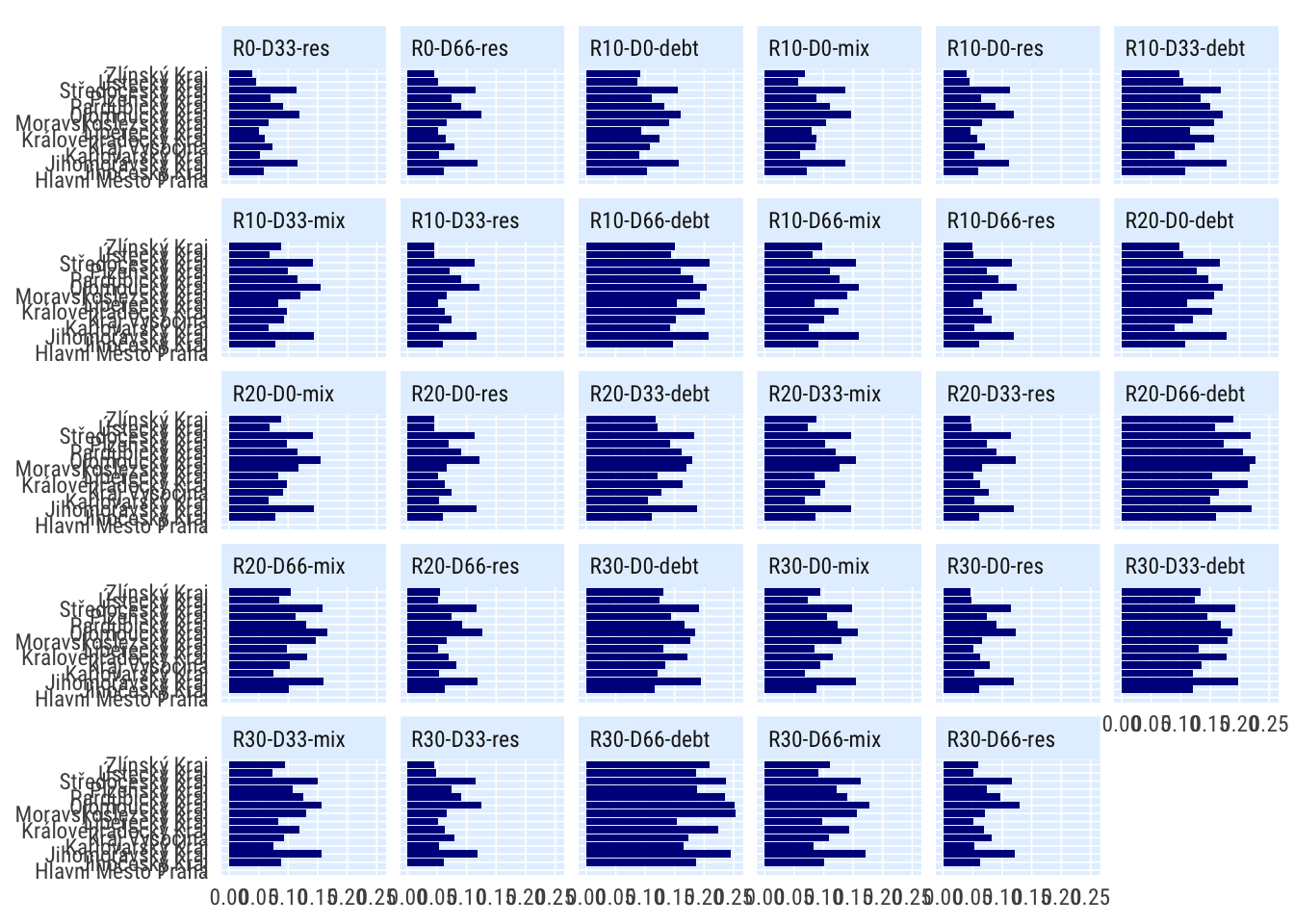
Podle velikosti obce
indikatory %>%
filter(per_yr %in% 2019:2020,
# scenario %in% c("S1", "S4", "S0"),
) %>%
mutate(bilance_neg = rozp_odp > .6) %>%
filter(str_detect(scenario, "R(0|10|20|30)*(\\-(0|33|66))*")) %>%
group_by(scenario, grp = katobyv_nazev) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("^R[0-9]")), ~./R0) %>%
select(-R0, -R) %>%
pivot_longer(cols = starts_with("R"), names_to = "scenario") %>%
# mutate(grp = fct_reorder(grp, value)) %>%
ggplot(aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
# scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("both", multiplot = T)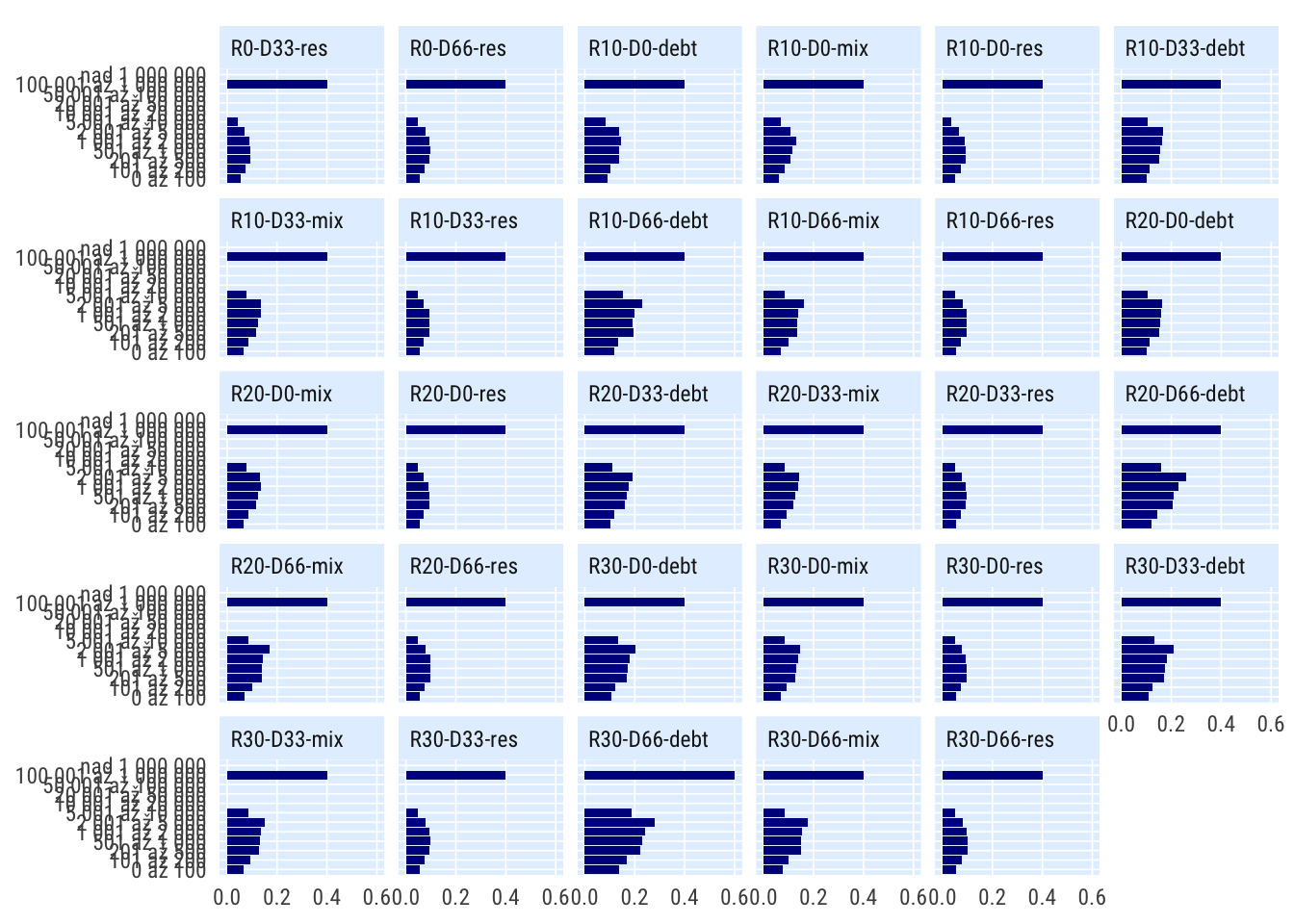
Podle typu obce
indikatory %>%
filter(per_yr %in% 2019:2020,
# scenario %in% c("S1", "S4", "S0"),
) %>%
mutate(bilance_neg = rozp_odp > .6) %>%
filter(str_detect(scenario, "R(0|10|20|30)*(\\-(0|33|66))*")) %>%
group_by(scenario, grp = typobce) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("^R[0-9]")), ~./R0) %>%
select(-R0, -R) %>%
pivot_longer(cols = starts_with("R"), names_to = "scenario") %>%
# mutate(grp = fct_reorder(grp, value)) %>%
ggplot(aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
# scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("both", multiplot = T)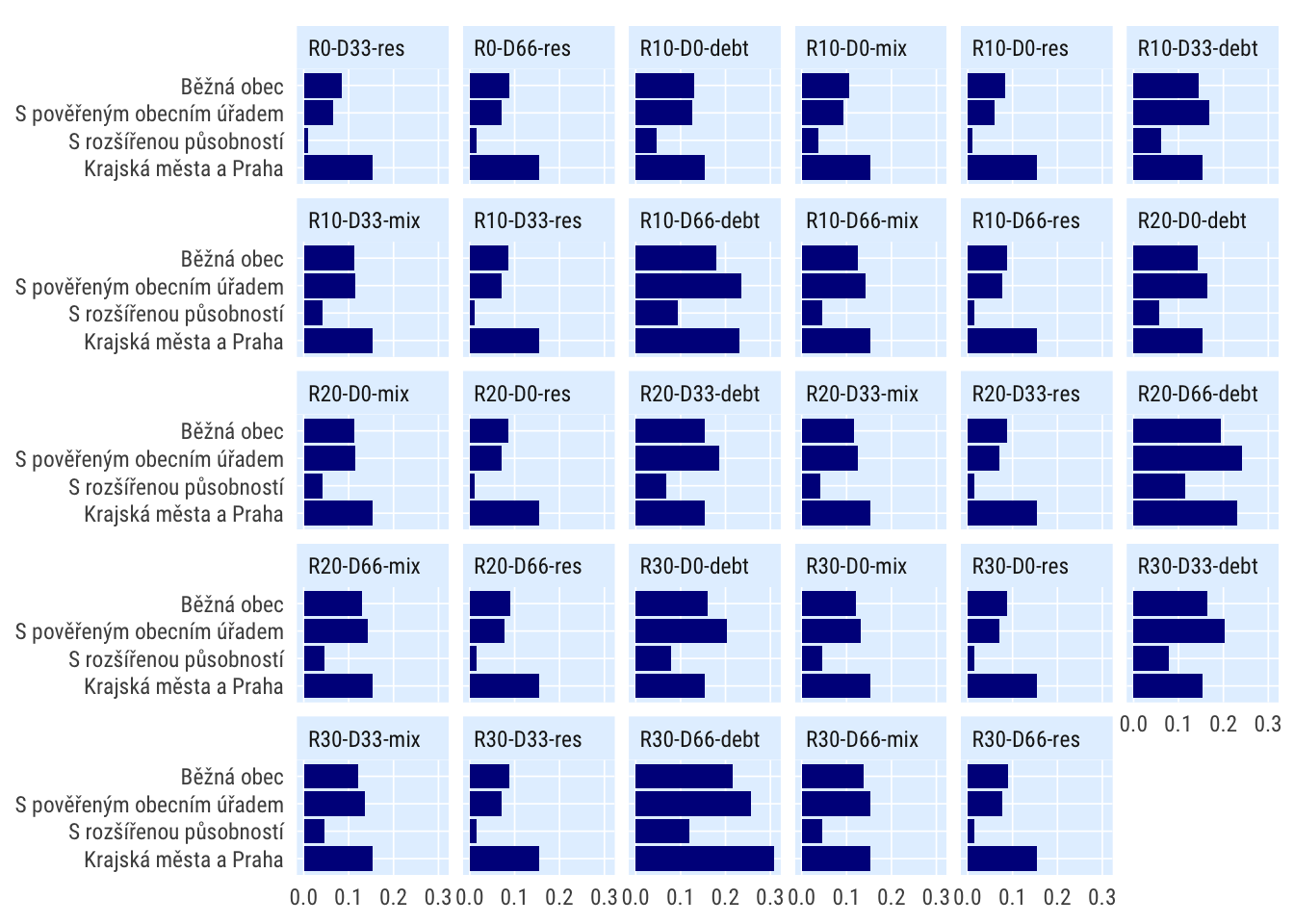
V čase: zjednodušený indikátor
Zjednodušení pouze na příjmy v posledním roce, abychom eliminovali artefakt, kdy se okno čtyřletého průměru posouvá do roků s vyššími příjmy.
Celkem
plot_percent(indikatory %>% filter(per_yr > 2012), rozp_odp_1yr > 0.6) +
expand_limits(y = c(0, 0.35)) +
scale_colour_discrete()
Rozdělení
indikatory %>%
filter(per_yr %in% 2019:2020,
# scenario %in% c("S1", "S0", "S4", "R"),
rozp_odp_1yr < 2.5) %>%
ggplot(aes(scenario, rozp_odp_1yr, fill = scenario)) +
geom_hline(yintercept = 0.6) +
# stat_ecdf(geom = "step", ) +
geom_violin(colour = NA) +
scale_x_discrete(labels = scales::label_wrap(15), drop = T) +
coord_flip() +
# scale_fill_manual(values = c("black", cols[c(7, 1:6)]), guide = "none") +
ptrr::theme_ptrr("scatter", legend.position = "bottom",
family = "IBM Plex Sans Condensed", multiplot = T) +
ptrr::scale_y_percent_cz(expand = ptrr::flush_axis,
n.breaks = 8)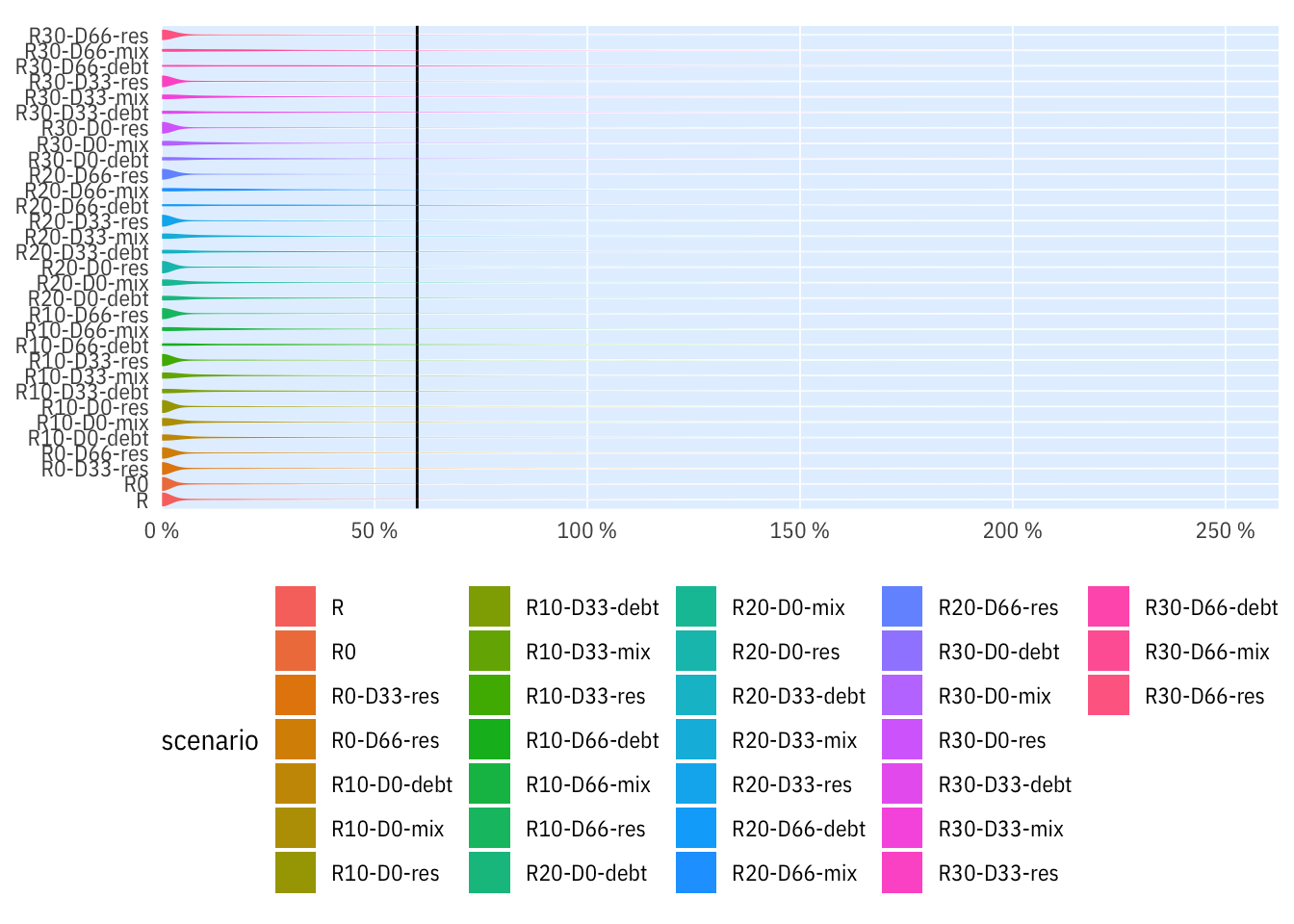
Podle kraje
plot_multi_percent(indikatory %>% filter(per_yr > 2012),
kraj, rozp_odp_1yr > 0.6) +
expand_limits(y = c(0, 0.45)) +
theme(legend.position = "bottom", legend.title = element_blank()) +
guides(colour = guide_legend(nrow = 4))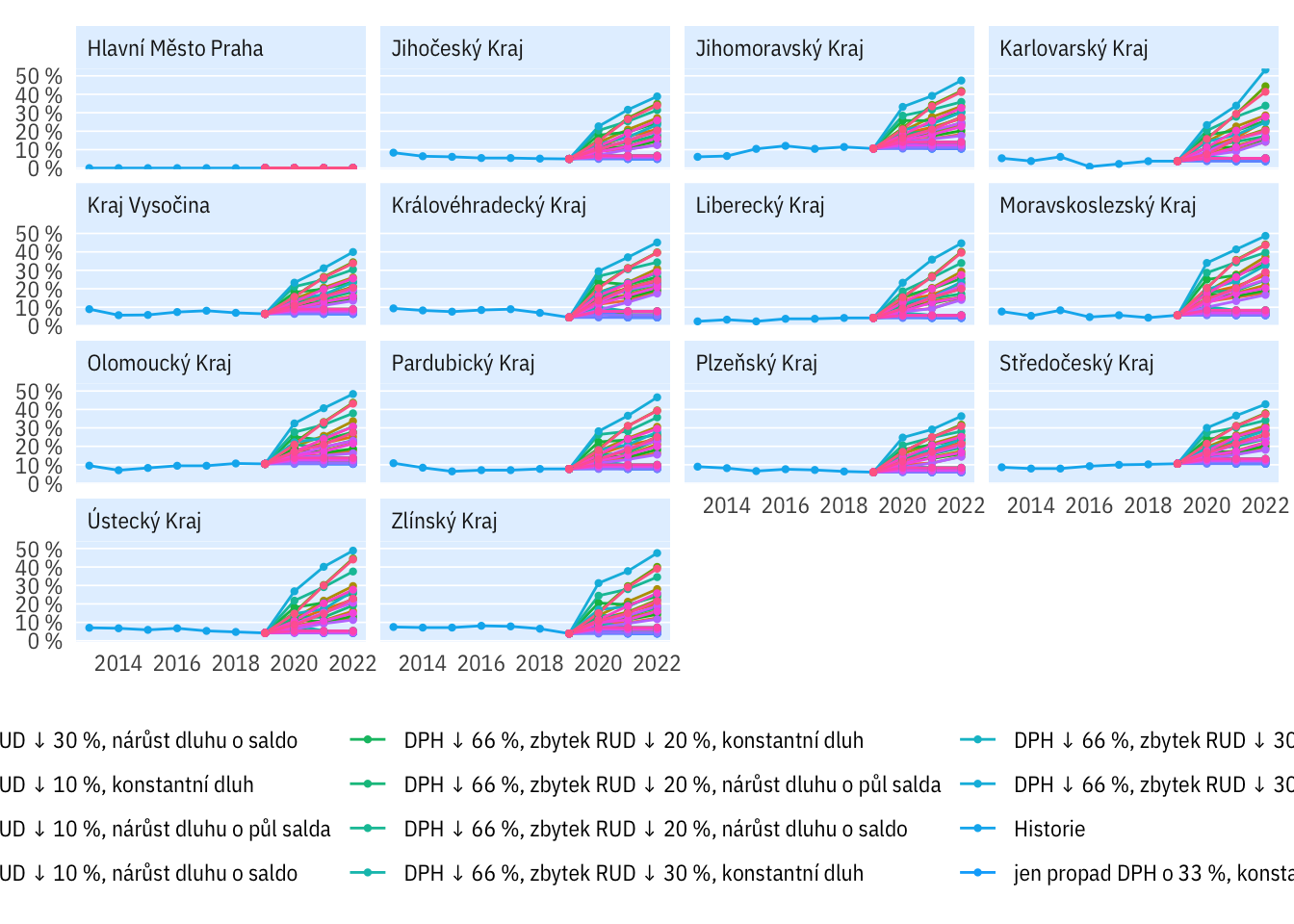
Podle velikosti obcí
plot_multi_percent(indikatory, katobyv_nazev, rozp_odp_1yr > 0.6) +
theme(legend.position = "bottom", legend.title = element_blank()) +
guides(colour = guide_legend(nrow = 4))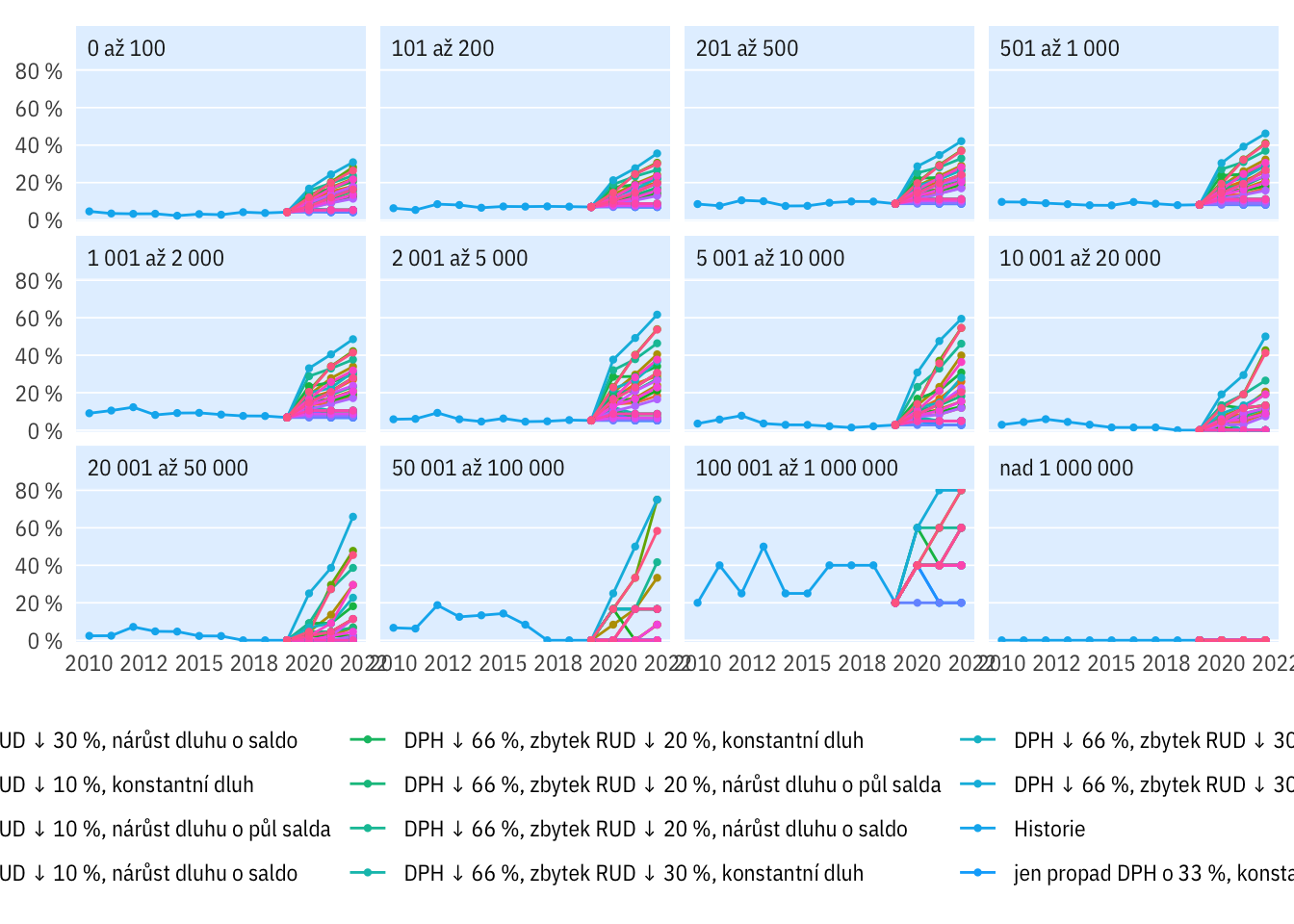
Podle typu obcí
plot_multi_percent(indikatory, typobce, rozp_odp_1yr > 0.6) +
theme(legend.position = "bottom", legend.title = element_blank()) +
guides(colour = guide_legend(nrow = 4)) +
scale_colour_discrete()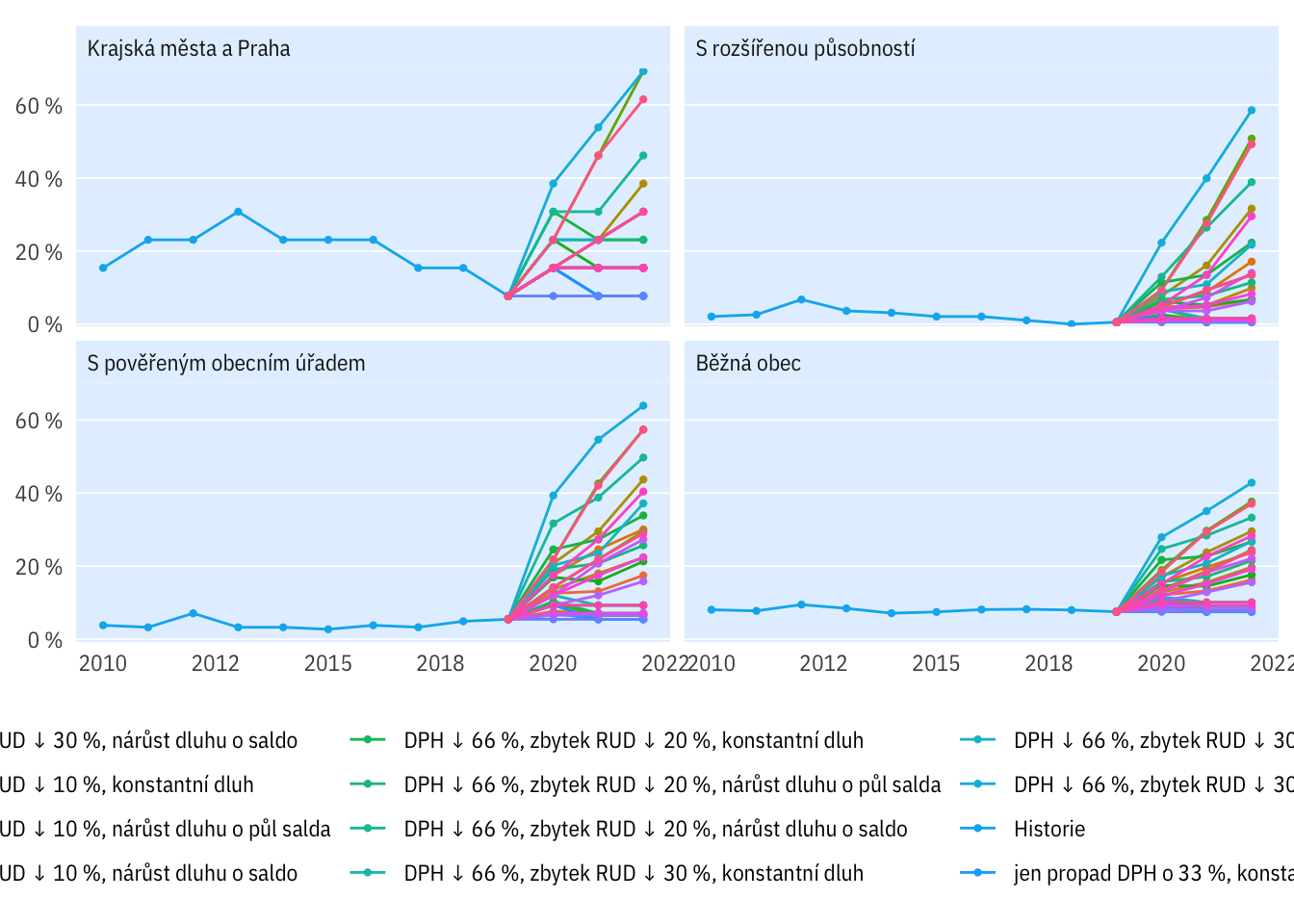
2020 x baseline: zjednodušený indikátor
Zjednodušení pouze na příjmy v posledním roce, abychom eliminovali artefakt, kdy se okno čtyřletého průměru posouvá do roků s vyššími příjmy.
Celkem
indikatory %>%
filter(per_yr %in% c(2019:2020),
# scenario %in% c("S1", "S4", "S0"),
) %>%
mutate(bilance_neg = rozp_odp_1yr > 0.6) %>%
group_by(scenario) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[1-3]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-9]"), names_to = "scenario") %>%
ggplot(aes(value, scenario)) +
geom_col() +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("x", multiplot = T)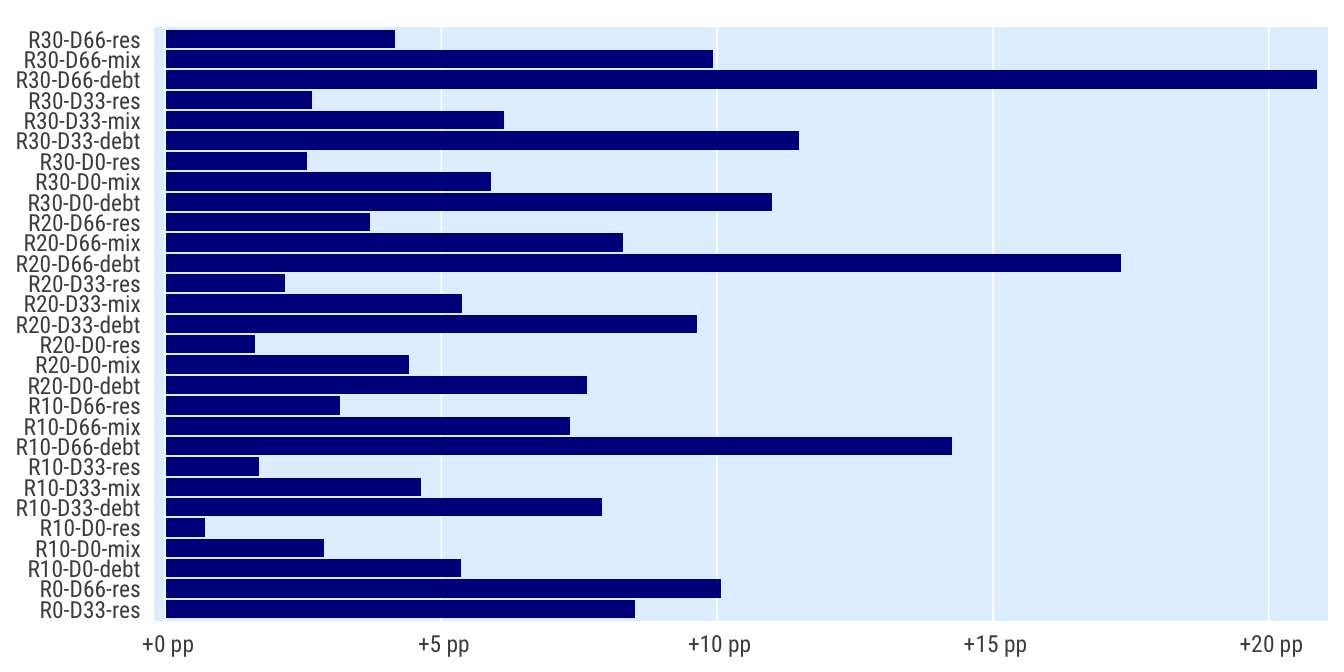
Podle kraje
indikatory %>%
filter(per_yr %in% 2019:2020,
# scenario %in% c("S1", "S4", "S0"),
) %>%
mutate(bilance_neg = rozp_odp_1yr > .6) %>%
group_by(scenario, grp = kraj) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[0-3]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-9]"), names_to = "scenario") %>%
mutate(grp = fct_reorder(grp, value)) %>%
ggplot(aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("x", multiplot = T)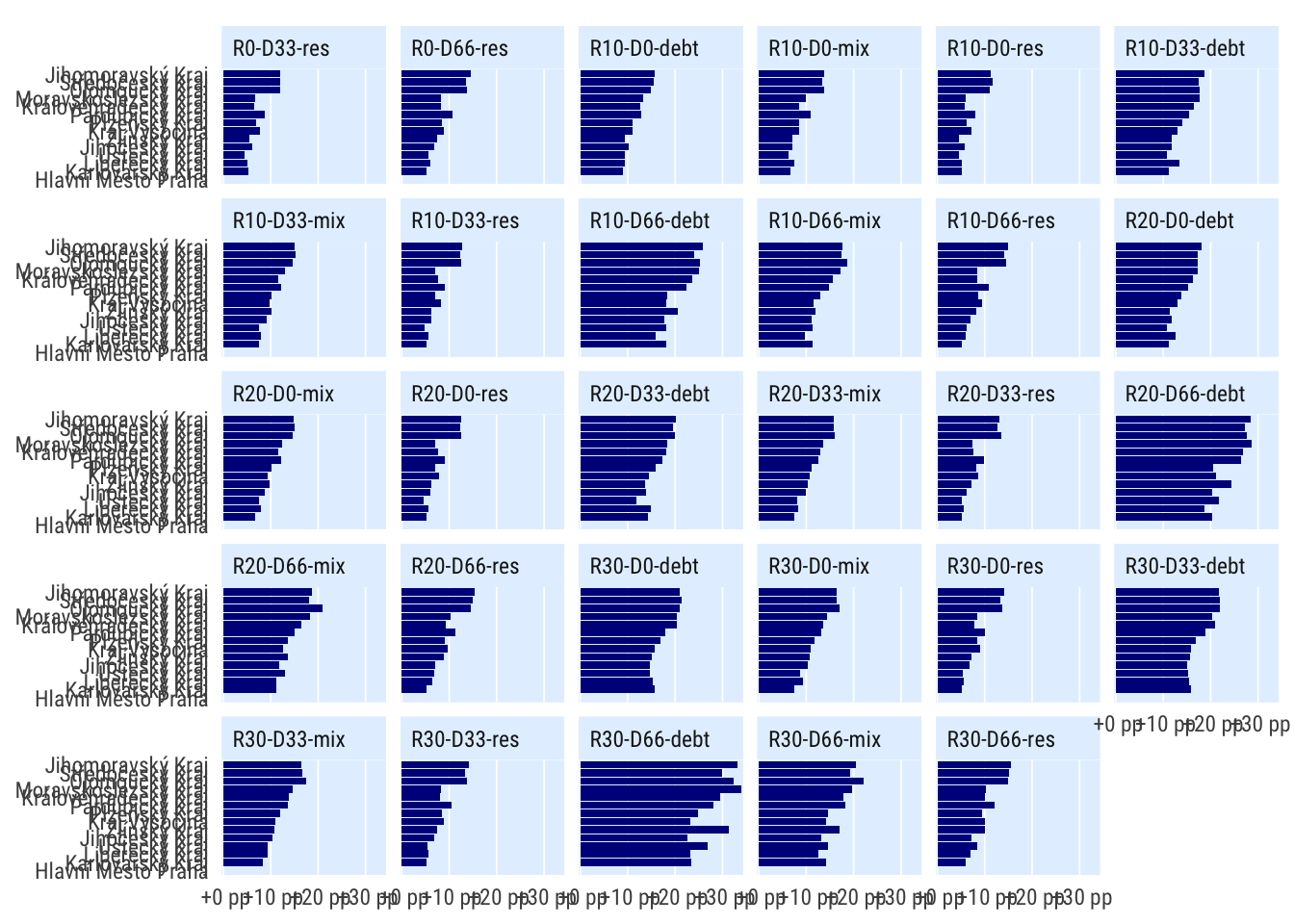
Podle velikosti obce
indikatory %>%
filter(per_yr %in% 2019:2020,
# scenario %in% c("S1", "S4", "S0"),
) %>%
mutate(bilance_neg = rozp_odp_1yr > .6) %>%
group_by(scenario, grp = katobyv_nazev) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[1-9]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-9]"), names_to = "scenario") %>%
# mutate(grp = fct_reorder(grp, value)) %>%
ggplot(aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("both", multiplot = T)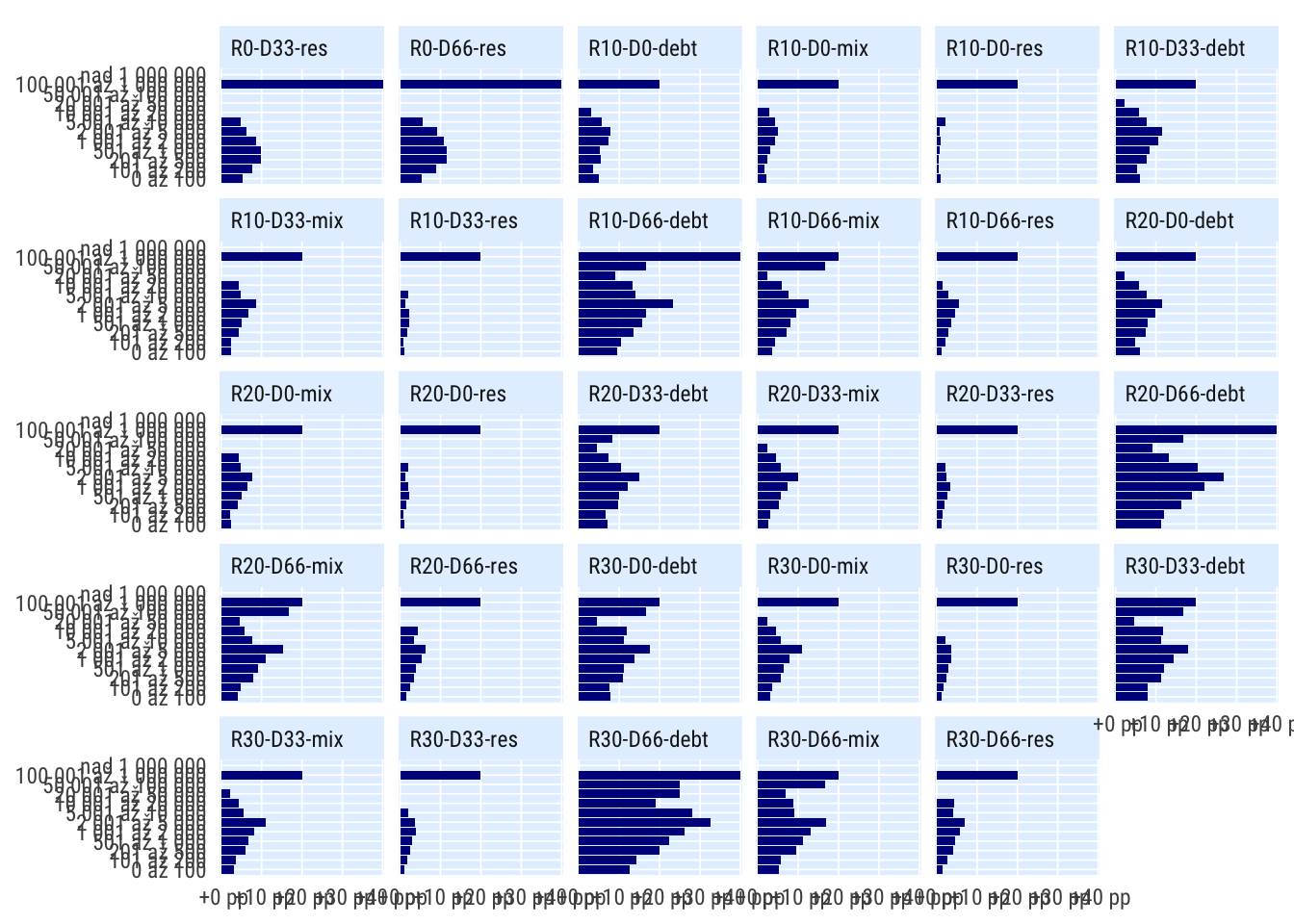
Podle typu obce
indikatory %>%
filter(per_yr %in% 2019:2020,
# scenario %in% c("S1", "S4", "S0"),
) %>%
mutate(bilance_neg = rozp_odp_1yr > .6) %>%
group_by(scenario, grp = typobce) %>%
summarise(perc_minus = mean(bilance_neg, na.rm = T)) %>%
spread(scenario, perc_minus) %>%
mutate_at(vars(matches("R[0-3]")), ~.-R0) %>%
select(-R0) %>%
pivot_longer(cols = matches("R[0-9]"), names_to = "scenario") %>%
# mutate(grp = fct_reorder(grp, value)) %>%
ggplot(aes(value, grp)) +
geom_col() +
facet_wrap(~scenario) +
scale_x_percent_cz(suffix = " pp", prefix = " +") +
theme_ptrr("both", multiplot = T)